
ORIGINAL DRAFT
Most applications need to store persistent data in one form or another. The world of relational database systems is well explored and a well proven solution to many standard storage problems. Solutions vary from small, single-user databases to large-scale enterprise systems. For many applications, however, the requirements are too specific to use a relational database system or maybe the features of a commercial RDBMS are overkill for a given application.
This article centers on the development of a binary database system, based on a simple variant of a heap file model. Heap solutions are common in memory management systems. The idea is simple enough. A free block of memory is allocated, on-demand and kept track of by a memory manager, which in turn keeps tabs on free blocks of memory using a linked list. When a block is allocated, it gets removed from the free list. When the block is released, it gets added back to the free list. Allocated blocks are assumed to be reachable through a handle or pointer to the specified memory locations.
As the heap gets exercised, memory blocks get fragmented. With allocated and free blocks interlaced in small bundles, finding a block for a given size is an interesting problem. Most memory managers do some garbage collection, merging contiguous free blocks back together to make space reclamation more efficient. When we look for a new block we can either seek the best match, which requires a full traversal of our free list, or settle for the first suitable match, which turns out to be typically more efficient and simpler. To avoid repeating unnecessary traversals, we can keep track of the last allocated position and continue from there, along the free list, the next time we get asked for a new block.
I mentioned that our implementation would be a variant on the heap file. Typical heap file implementations use a linked list for the free list, which saves space and deals effectively with the problem. In a persistent store, it’s often useful to control the logical order of records. In a relational database, this is done with indexes, which keep keys sorted for fast access. In a heap, there is a logical order, which is different than the physical order that the records are stored in.
While it’s not necessary to support traversal of an allocated list of records, I’ve found this functionality surprisingly useful in other projects, so this implementation supports an API that lets you walk records, both forward and backward. To do this, we’ll use a chain (a doubly-linked list) instead of a simple linked list and we’ll keep two separate chains, one for free and another for allocated blocks. The resulting code makes it easy to insert records at a given logical position, either before or after a specified record, which adds flexibility at the cost of a few bytes per record. We’ll use the same mechanism for our free list, allowing us to reuse the same code and minimize the risk of errors.
Here are the fundamental requirements of this design:
- Make the code readable and reusable without sacrificing performance.
- Make it possible to deal with arbitrary record sizes up to a maximum of 2 gigabytes.
- Make record positions accessible to the user, supporting logical record traversal.
- Make good use of free space reclamation and optimize the code to minimize waste.
The following diagram shows how the database file is to be structured. Each file contains a header with a free and a used chain root object. Pointers are directed forward to the next record in each chain. As the diagram illustrates, the last record links back to the first to form a loop. Each record header contains additional information which we’ll be describing in a moment.
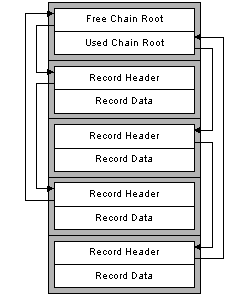
Figure 1: Free and Used Record Chains.
Figure 2 shows the structure of a database header, which reveals the nested approach I decided to take. The DBHeader object contains two DBChainRoot objects. Each DBChainRoot extends the DBChainNode class and supplements it with a field called current, which manages the current search location. Figure 2 illustrates this as a containment relationship though the DBChainRoot class actually extends DBChainNode so that the same node management code can be applied to deletion and insertion operations. DBHeader contains two DBChainRoot objects, which are used to track free and used blocks in the database.
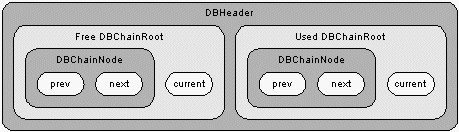
Figure 2: Database Header Structure.
Each record has a structure that includes a DBRecordHeader object. Figure 3 shows that a DBRecord object contains both the DBRecordHeader and the actual binary data for a record. The DBRecordHeader contains a DBChainNode and a DBRecordInfo object describing the used block chain and some meta data about the record, respectively. The type is either USED or FREE, depending on whether the record is currently in use or not. It would be free if the block was reclaimed by a deletion operation.
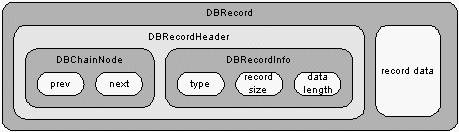
Figure 3: Database Record Structure.
Figure 4 shows the object relationships between the classes in this project, viewed primarily in terms of containment. Remember that the DBChainRoot is really an extension of DBChainNode so the node reference is actually inherited.
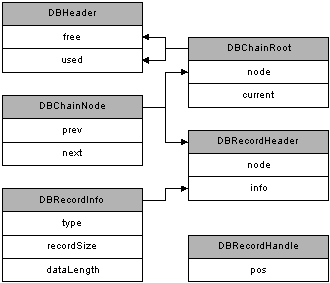
Figure 4: Object Relationships.
The DBRecordHandle is a way of handling immutable position references. A DBRecordHandle is returned at insertion time and can be used to lookup or delete an object. It contains nothing more than the exact position in the file at which the record exists but encapsulating this position like this ensures that handles are not involved in calculations the way a long integer might be. While a handle is in fact positional, it is mean to be used as a unique identifier to access an record in the database.
A few additional objects are part of this design. These include a DBConstants interface which declares a number of useful constants; a DBException object for handling exceptions in a uniform manner; and the main DBDatabaseFile object, which provides a high level interface to the database subsystems. In addition, we’ll implement a DBTestHarness class to handle regression and feature testing.
I’ve included a couple of wrappers to accommodate String and Serializable object records but these are not the focus of our implementation, included only to demonstrate the flexibility of this design. You can find the StringDBFile and ObjectDBFile classes online at www.java-pro.com. The StringDBFile class wraps string-handling methods around the DBDatabaseFile class and ObjectDBFile supports the serialization, storage and retrieval of Java objects.
The API exposed by the DBDatabaseFile is intentionally sparse. This type of database requires little more than the ability to lookup, delete, insert and list records. To accomplish this, the following public methods are implemented. Note that each of these throws a DBException, which has been left out for convenience.
The lookupRecord method allows programmers to retrieve a record by handle.
public byte[] lookupRecord(DBRecordHandle handle)</CODE></P>
The deleteRecord method permits deletion of an existing record.
public boolean deleteRecord(DBRecordHandle handle)</CODE></P>
Since relative logical record positioning is part of our design, two methods support insertion before or after a given record location. For convenience, a default insertion method is provided, which inserts a record at the end of the chain.
public DBRecordHandle insertRecord(byte[] record)
public DBRecordHandle insertRecordAfter(DBRecordHandle handle, byte[] record)
public DBRecordHandle insertRecordBefore(DBRecordHandle handle, byte[] record)
Its also important to be able to traverse the database. There are four methods to support the retrieval of handles which can then be used to lookup the records.
public DBRecordHandle getFirstHandle()
DBRecordHandle getLastHandle()</CODE></P>
DBRecordHandle getNextHandle(DBRecordHandle handle)
DBRecordHandle getPrevHandle(DBRecordHandle handle)
This simple set of methods is sufficient to access and manage records in the database system. Let’s move on to an explanation of each implemented class. We’ll cover them in bottom-up order, building primitive components first and assembling them as we cover subsequent objects. Due to space limitations most of the classes will not be listed in print.
Java does not include support for C-style header files nor does it accommodate multiple class inheritance. Constants are typically declared as static final member variables. To include them directly in the classes that use them, it’s common and useful to declare them in an interface class, especially when the same constants may need to be used in several classes which do not share any other relationship. Furthermore, it’s necessary to reference them explicitly, with a class name prefix, unless they are locally included. By implementing the DBConstant interface, objects can share the same values, and access them without long qualifiers so maintenance is facilitated.
Most exceptions thrown by a database file are likely to be IOExceptions. This is not typically very instructive. More explicit information can be provided by low level methods by using a common exception class. The DBException class inherits from the standard Exception class. Low level methods throw DBExceptions whenever any other exception is caught, with an explanation of what went wrong. The normal stack trace provides explicit information about what went wrong and the message will be sufficiently indicative of the problem to make debugging more effective.
The DBRecordHandle object is designed to encapsulate file pointers in such a a way that they cannot be modified directly. If the file position was referenced as a long integer, developers might accidentally apply mathematical operations or confuse them with other long integers in their programs. To force encapsulation, a DBRecordHandle can be created with a pointer value, but it cannot be modified. This immutability provides the desired protection and has the added benefit of being wrapped in an object which can be inserted in various containers (such as a Hashtable or Vector) without modification.
The DBChainNode object provides forward (next) and backward (prev) pointers in a chain. Two chains are supported by the database, capturing free and used records. By keeping chain-related methods encapsulated in the DBChainNode object, operations like insertion and deletion are greatly simplified. The logic, in fact, is eminently more readable and manageable this way. Two objects encapsulate the DBChainNode in their inner workings, DBChainRoot and DBRecordHeader. In each case, the node is first in the read and write sequence to allow nodes to be read independently using the same pointers. Each of the pointers point to the precise point in the file where another DBChainNode can be read. By default, new nodes are self referential, pointing to themselves until the pointers are adjusted.
Listing 1 shows the code for DBChainNode. We expect a RandomAccessFile reference and a file position in the constructor and provide a toString method to make debugging as easy as possible. The file access takes place in one of four methods, two of which write while the other two read a DBChainNode element. Both the read and write methods provide absolute and relative access. Absolute access implies seeking to specified position before reading or writing data. The relative variants assume the file pointer is already positioned. The relative option is important when compound elements are written or read from the file. By convention the containing class will typically position the pointer.
The DBChainNode class also implements a trio of methods that allow the node to remove itself from a doubly-linked list and to insert itself both before or after another node. You’ll notice that most of the methods throw a DBException if something unexpected happens and that many of them include additional debugging information to help focus in on the problem. The last method of note is called sizeOf. It returns a fixed integer value indicating the storage requirements for the object data. Unfortunately, Java does not include a method to measure this so if you modify this code, you’ll have to be especially careful to keep this value correct.
The DBChainRoot object extends the behavior of the DBChainNode by adding a pointer to the current search node. This is useful for optimizing searches for free records and avoids problems related to starting from the beginning of the file each time. A DBChainRecord can be read and written and the contained DBChainNode object will be read or written at the same time. This makes it easier to handle explicit references to a node or more general references to the root node, and its current location extension, interchangeably. Since the DBChainRoot extends the DBChainNode object, it can be referenced by the same deletion and insertion methods supported in the DBChainNode object.
The first two elements in a database file are the DBChainRoot objects for the free and used chains. The free chain provides access to the circular chain which holds references to deleted records. These records can be reclaimed when new records are inserted, whenever the new record is smaller than a given free record. The logical record sequence is not affected by the physical location of the record thanks to the used record chain. This second, used chain is rooted in the same database header. The DBDatabaseHeader class provides methods to allow reading and writing both chain roots in a single place. The chain root can be accessed through variables provided in the database header.
Database records support variable length entries which may be smaller than the record space allocated. This happens primarily when records are reclaimed from the free list. A DBRecordInfo object manages a type field which marks the record as FREE or USED. This is not strictly necessary if nothing goes wrong but it makes it possible to rebuild the database if chain integrity is in question. By traversing each record, reading its header and date, a new copy of the database can be build by looking for the records marked as USED. The DBRecordInfo object stores both record size and the data length integers. This puts a limit on each BLOB (Binary Large Object) record at 2 gigabytes, which seems more than generous. The record size and data length values will often be the same if a record was appended, but tends to differ if the record was reclaimed from the free chain at insertion time.
Listing 2 shows the DBRecordHeader class, which provides encapsulation for the DBChainNode and DBRecordInfo objects. For each record, this header is written in the specified sequence, followed by the record data itself. You’ll find five methods in this class, a sizeOf method which reflects the combined size of the encapsulated DBChainNode and DBRecordInfo data. The rest of the methods are variants on the writeAbsolute, writeRelative and readAbsolute, readRelative pattern we saw before.
Within the protected package, of course, the code can access subobjects directly, so I’ve been rather sparse with accessor methods, though in a commercial implementation this would be highly recommended. Access is still protected from objects outside the package given that all instance variables are declared as protected.
The high-level interface is supported by the DBDatabaseFile object. Each of the API methods presented earlier is implemented in this class. These calls are easily abstracted to handle specific types of records by extending the base class. For example, extending the lookupRecord, deleteRecord and insertRecord methods to support String objects, Serializable objects or other specific object types is fairly straight forward.
Listing 3 shows the code for DBDatabaseFile. The constructor expects a valid file name and knows enough to create a new database if the file length is zero. The close method should be called when you’re finished access the database file. You’ll find a few utility methods in the first part of the file, including findFreeRecord and splitRecord. The splitRecord method reclaims left over parts of a larger record when a sufficiently small portion is reclaimed, adding the new unused record to the free list. The rest of the methods implement the interface we spoke of earlier and are heavily commented in order to keep to code as easy to read as possible.
You may have noticed that this implementation has a few shortcomings, which would have to be resolved in a high-end production system, not the least of which is the lack of support for concurrency or transactions. While these could certainly be added, if these are part of your requirements, a standard RDBMS might be a better choice. Traversing the database using the getFirstHandle and getNextHandle methods while performing record deletions can lead to serious problems, for example, and no attempt has been made to avoid collisions.
Astute readers will also notice that a large database without a suitable indexing system could easily become impractical. The approach presented here is useful where record order is important but key-based lookups are not paramount, though storing DBRecordHandle objects in a B+Tree would certainly overcome this minor deficiency.
You’ll find this code primarily useful in small, single-user projects that need access to lists of ordered data stored on disk. This approach provides an efficient mechanism for disk-based record insertion and deletion, complete with bi-directional traversal. I hope you find this implementation as interesting as it was for me to develop.
Listing 1
import java.io.*;
public class DBChainRoot extends DBChainNode
{
protected long current = NULL;
public DBChainRoot(RandomAccessFile file, long pos)
{
super(file, pos);
}
public static int sizeOf()
{
return DBChainNode.sizeOf() + 8;
}
public void writeRelative() throws DBException
{
long debug = 0;
try
{
debug = file.getFilePointer();
super.writeRelative();
file.writeLong(current);
}
catch (Exception e)
{
throw new DBException(
"Unable to write record chain root at " + debug);
}
}
public void writeAbsolute() throws DBException
{
try
{
super.writeAbsolute();
file.writeLong(current);
}
catch (Exception e)
{
throw new DBException(
"Unable to write record chain root at " + pos);
}
}
public void readRelative() throws DBException
{
long debug = 0;
try
{
debug = file.getFilePointer();
super.readRelative();
current = file.readLong();
}
catch (Exception e)
{
throw new DBException(
"Unable to read record chain root at " + debug);
}
}
public void readAbsolute() throws DBException
{
try
{
super.readAbsolute();
current = file.readLong();
}
catch (Exception e)
{
throw new DBException(
"Unable to read record chain root at " + pos);
}
}
}
Listing 2
import java.io.*;
public class DBRecordHeader
{
protected RandomAccessFile file;
protected long pos;
protected DBChainNode node;
protected DBRecordInfo info;
public DBRecordHeader(RandomAccessFile file, long pos)
{
this.file = file;
this.pos = pos;
node = new DBChainNode(file, pos);
info = new DBRecordInfo(file, pos + DBChainNode.sizeOf());
}
public static int sizeOf()
{
return DBChainNode.sizeOf() + DBRecordInfo.sizeOf();
}
public void writeRelative() throws DBException
{
long debug = 0;
try
{
debug = file.getFilePointer();
node.writeRelative();
info.writeRelative();
}
catch (Exception e)
{
throw new DBException(
"Unable to write record header at " + debug);
}
}
public void writeAbsolute() throws DBException
{
try
{
file.seek(pos);
writeRelative();
}
catch (Exception e)
{
throw new DBException(
"Unable to write record header at " + pos);
}
}
public void readRelative() throws DBException
{
long debug = 0;
try
{
debug = file.getFilePointer();
node.readRelative();
info.readRelative();
}
catch (Exception e)
{
throw new DBException(
"Unable to read record header at " + debug);
}
}
public void readAbsolute() throws DBException
{
try
{
file.seek(pos);
readRelative();
}
catch (Exception e)
{
throw new DBException(
"Unable to read record header at " + pos);
}
}
}
Listing 3
import java.io.*;
import java.util.*;
public class DBDatabaseFile implements DBConstants
{
protected RandomAccessFile file;
protected String filename;
protected DBHeader header;
/*
---------------------------------------------------------------------
Database calls
---------------------------------------------------------------------
*/
/**
* Constructor opens a random access file and creates the
* database header if necessary. If the file already exists,
* the database header is read from the front of the file.
* @param filename The name of the database file.
**/
public DBDatabaseFile(String filename) throws DBException
{
try
{
this.filename = filename;
file = new RandomAccessFile(filename, "rw");
header = new DBHeader(file);
if (file.length() == 0)
{
header.writeAbsolute();
}
else
{
header.readAbsolute();
}
}
catch (Exception e)
{
throw new DBException(e.getMessage());
}
}
/**
* Close the database
**/
public void close() throws DBException
{
try
{
file.close();
}
catch (Exception e)
{
throw new DBException(e.getMessage());
}
}
/*
---------------------------------------------------------------------
Internal support methods
---------------------------------------------------------------------
*/
/**
* Find a record large enough to accomodate the required size
* and return the position, or return -1 if none was found.
**/
private long findFreeRecord(long required) throws DBException
{
try
{
DBChainNode node = header.free;
node.readAbsolute();
DBRecordHeader head;
long position = node.next;
// If position points to the root node, we're looping
while (position != node.pos)
{
head = new DBRecordHeader(file, position);
head.readAbsolute();
// Found a big enough record, return position
if (head.info.recordSize >= required)
{
return head.pos;
}
// Keep searching with the next record
else
{
position = head.node.next;
}
}
// No suitable record available
return NULL;
}
catch (Exception e)
{
throw new DBException(e.getMessage());
}
}
/**
* Break a record into a used and free record if the data length
* is sufficiently small compared to the record size.
**/
private void splitRecord(long pos) throws DBException
{
try
{
DBRecordHeader head = new DBRecordHeader(file, pos);
head.readAbsolute();
int dataLength = head.info.dataLength;
int diff = head.info.recordSize - dataLength;
// We need at least enough room for the header
if (diff < DBRecordHeader.sizeOf()) return ;
// Shrink the existing record
head.info.recordSize = dataLength;
head.writeAbsolute();
// Create a new free record for the rest
pos += DBRecordHeader.sizeOf() + dataLength;
head = new DBRecordHeader(file, pos);
// Insert the new record into the free chain
head.node.insertBefore(header.free);
head.info.type = FREE;
head.info.recordSize = diff - DBRecordHeader.sizeOf();
head.info.dataLength = diff - DBRecordHeader.sizeOf();
head.writeAbsolute();
}
catch (Exception e)
{
throw new DBException(e.getMessage());
}
}
/*
---------------------------------------------------------------------
Record access methods
---------------------------------------------------------------------
*/
/**
* Lookup a record at the specified handle location.
**/
public byte[] lookupRecord(DBRecordHandle handle) throws DBException
{
try
{
// Argument validation
if (handle.pos < 0 || handle.pos > file.length())
new DBException("Invalid record handle");
DBRecordHeader head = new DBRecordHeader(file, handle.pos);
head.readAbsolute();
byte[] record = new byte[head.info.dataLength];
file.read(record);
return record;
}
catch (Exception e)
{
throw new DBException(e.getMessage());
}
}
/**
* Delete a record at the specified handle location.
**/
public boolean deleteRecord(DBRecordHandle handle)
throws DBException
{
try
{
// Argument validation
if (handle.pos < 0)
new DBException("Invalid record handle");
if (handle.pos > file.length())
new DBException("Invalid record handle");
DBRecordHeader head = new DBRecordHeader(file, handle.pos);
head.readAbsolute();
head.node.remove();
head.node.insertBefore(header.free);
return true;
}
catch (Exception e)
{
throw new DBException(e.getMessage());
}
}
/**
* Insert a new record, adding it to the active chain.
**/
public DBRecordHandle insertRecord(byte[] record)
throws DBException
{
return insertRecordAfter(
new DBRecordHandle(header.used.pos), record);
}
/**
* Insert a new record, adding it after the specified position.
**/
public DBRecordHandle insertRecordAfter(
DBRecordHandle handle, byte[] record)
throws DBException
{
try
{
// Argument validation
if (record == null)
new DBException("Null record");
if (record.length < 0) throw
new DBException("Record too large");
if (handle.pos < 0)
new DBException("Invalid record handle");
if (handle.pos > file.length())
new DBException("Invalid record handle");
// Locate a suitable record for insertion
boolean append = false;
long pos = findFreeRecord(record.length);
// Append if no suitable record was found
if (pos == NULL)
{
append = true;
pos = file.length();
}
// Read the chain node for the relative record
DBChainNode node = new DBChainNode(file, handle.pos);
node.readAbsolute();
DBRecordHeader head = new DBRecordHeader(file, pos);
// Read the header if this is an existing record
if (!append)
{
head.readAbsolute();
// Remove from free list
head.node.remove();
}
// Link into used list, before node (after last record)
head.node.insertBefore(node);
head.info.type = USED;
// Specify record length only if new record
if (append)
{
head.info.recordSize = record.length;
}
head.info.dataLength = record.length;
// Write out the header and record data
head.writeAbsolute();
file.write(record);
// Split the record if there's too much free space
splitRecord(pos);
return new DBRecordHandle(pos);
}
catch (Exception e)
{
throw new DBException(e.getMessage());
}
}
/**
* Insert a new record, adding it before the specified position.
**/
public DBRecordHandle insertRecordBefore(
DBRecordHandle handle, byte[] record)
throws DBException
{
try
{
// Argument validation
if (record == null)
new DBException("Null record");
if (record.length < 0) throw
new DBException("Record too large");
if (handle.pos < 0 || handle.pos > file.length())
new DBException("Invalid record handle");
// Locate a suitable record for insertion
boolean append = false;
long pos = findFreeRecord(record.length);
// Append if no suitable record was found
if (pos == NULL)
{
append = true;
pos = file.length();
}
// Read the chain node for the relative record
DBChainNode node = new DBChainNode(file, handle.pos);
node.readAbsolute();
DBRecordHeader head = new DBRecordHeader(file, pos);
// Read the header if this is an existing record
if (!append)
{
head.readAbsolute();
// Remove from free list
head.node.remove();
}
// Link into used list, after node (before first record)
head.node.insertAfter(node);
head.info.type = USED;
// Specify record length only if new record
if (append)
{
head.info.recordSize = record.length;
}
head.info.dataLength = record.length;
// Write out the header and record data
head.writeAbsolute();
file.write(record);
// Split the record if there's too much free space
splitRecord(pos);
return new DBRecordHandle(pos);
}
catch (Exception e)
{
throw new DBException(e.getMessage());
}
}
/*
---------------------------------------------------------------------
Iterators for traversing records by handle
---------------------------------------------------------------------
*/
/**
* Get the first record handle in the used chain.
**/
public DBRecordHandle getFirstHandle()
throws DBException
{
try
{
DBChainNode node = new DBChainNode(file, header.used.next);
node.readAbsolute();
return new DBRecordHandle(node.next);
}
catch (Exception e)
{
throw new DBException(e.getMessage());
}
}
/**
* Get the last record handle in the used chain.
**/
public DBRecordHandle getLastHandle()
throws DBException
{
try
{
DBChainNode node = new DBChainNode(file, header.used.prev);
node.readAbsolute();
return new DBRecordHandle(node.next);
}
catch (Exception e)
{
throw new DBException(e.getMessage());
}
}
/**
* Get the next record handle in the used chain.
**/
public DBRecordHandle getNextHandle(DBRecordHandle handle)
throws DBException
{
try
{
DBChainNode node = new DBChainNode(file, handle.pos);
node.readAbsolute();
return new DBRecordHandle(node.next);
}
catch (Exception e)
{
throw new DBException(e.getMessage());
}
}
/**
* Get the previous record handle in the used chain.
**/
public DBRecordHandle getPrevHandle(DBRecordHandle handle)
throws DBException
{
try
{
DBChainNode node = new DBChainNode(file, handle.pos);
node.readAbsolute();
return new DBRecordHandle(node.prev);
}
catch (Exception e)
{
throw new DBException(e.getMessage());
}
}
public Enumeration elements()
{
return new DBRecordEnumeration(this);
}
}