
ORIGINAL DRAFT
Many applications provide text editing features and would benefit from simple syntax highlighting. Unfortunately, there’s little in the way of good published examples for implementing this feature using the Swing editing components. Sun’s Swing Connection offers an older article with sample code, but (other than being a out of date) the code is tightly coupled to the Java language parser. With Java 1.4’s regular expression support, it’s now an easy matter to define simple tokenizers that can accomplish what you need, with very little code. We’ll show how you can develop both a Java and XML highlighter in this article.
Because this column centers on Visual Components, I won’t be spending much time explaining regular expressions. O’Reilly has a great book called “Mastering Regular Expressions” that features good coverage of both the Java 1.4 regular expression support and regular expressions in general. We’ll develop a few classes to deal directly with regular expressions. The first is the RETokenizer class, which uses an inner class called Token that contains the token text, type and position in a document. We’ll use a class called RETypes to define the association between specific type names, the regular expressions that matches those tokens, and a color for highlighting. Two classes extend RETypes, REJavaTypes (which handles Java language syntax) and REXMLTypes (which handles XML document syntax).
In a number of cases, you’ll want provide more specificity for tokens that are of the same general type. For example, if would be nice to simply define atomic names in a single regular expression and then distinguish between them by matching entries in a list. Swing class names could be colored one way, while Java reserved word tokens would be a different color. Ideally, we’d like to let this behavior be data-driven, so you could list tokens in a file and change the entries any time new versions came along or whenever new class collections came along for which you wanted syntax highlighting. We’ll do this with a KeywordList class and a KeywordManager, to handle multiple lists.
The main work is done by a custom EditorDocument class, which extends DefaultStyledDocument. For convenience, we’ll implement a class called JEditor that extends JEditorPane. Each of our RETypes extensions, REJavaTypes and REXMLTypes will included an inner class that extends StyledEditorKit to override the createDefaultDocument method, returning our custom EditorDocument.
Before we drill into the code, I want to mention that this solution is not optimal. It reparses the whole document every time new text is entered or removed. Interestingly, this has no perceivable impact on performance for small documents on an 800 MHz machine. You can type and see tokens become highlighted and or lose their highlighting, based on the characters you add or remove. Code editors typically handle small documents in any case, so this kind of implementation will often be sufficient.
A faster solution might focus on the current line instead, looking back a line or two, or forward, based on the document type, then tokenizing only that portion of the code. My first draft took that direction but quickly became too tightly coupled to the document syntax. It was more important to me to demonstrate the technique that to optimize for speed. As such, you may want to edit the highlightSyntax method in EditorDocument to implement more document-specific behavior. Given the information in this article, this should be a fairly small step for you to take if you need to improve performance.
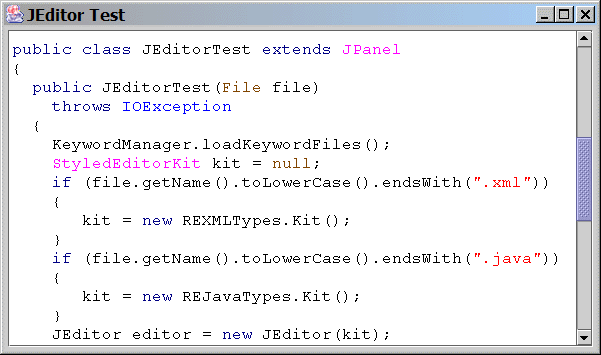
Figure 1: JEditor displaying syntax-highlighted Java source code.
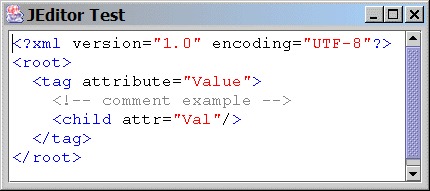
Figure 2: JEditor displaying a syntax-highlighted XML document.
Figures 1 and 2 show JEditor with either some Java source code and an XML document, respectively.
Let’s take a quick tour of the key classes. Figure 3 shows the class relationships in this project. You can see that the JEditor class relies on an EditorDocument, which extends the Swing DefaultStyledDocument class. The REXMLTypes and REJavaTypes classes extend RETypes and implement EditorDocument subclasses as inner classes (primarily because they are so short). The KeywordManager uses the KeywordList class to load word lists and color associations from files. These are used by the Java document since XML files are highlighted purely from syntax elements. The RETokenizer uses the RETypes to produce tokens and is used by the EditorDocument class to tokenize the text.
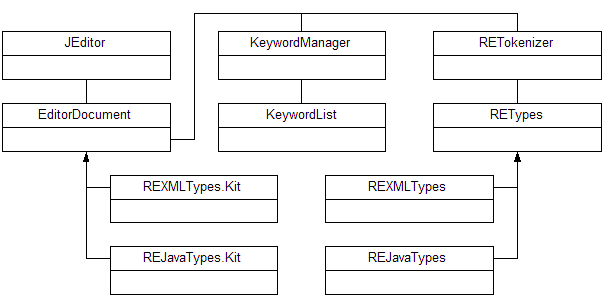
Figure 3: The JEditor classes include two EditorDocument and RETypes implementations to support both XML and Java syntax highlighting.
By extending both EditorDocument and RETypes, you can create syntax highlighting features for any format. The Keyword management is optional but, as you can see in Figure 1, helps distinguish specific tokens using different colors and tends to enhance readability with little in the way of complexity. The KeywordManager looks for files with two color lines followed by a list of words, one per line. The colors are defined as hexadecimal values for the foreground and background, respectively. KeywordManager and KeywordList classes are fairly straight forward, so we won’t spend much time looking at them more closely.
Instead, we’ll focus on the RETokenizer and EditorDocument, which are really the key to implementing syntax highlighting. Of course, all the files are available online for download at www.javapro.com. The JEditorTest class recognizes the ".java" and ".xml" file extensions and expects a single (file name) command line argument, so you can experiment with different files.
Listing 1 shows the code for RETokenizer, which relies heavily on an RETypes class to define lists of tokenizable elements. An REType is defined by a name, regular expression and color. RETypes is a linked list of RETypes.Type (inner class) instances and provides methods for adding these, counting them, and asking about the names, expressions and colors by index value. I’ve also implemented a setStyles method which uses the name and color values to set style attributes on a StyledDocument, in our case the EditorDocument, and a getExpression method which creates a compound Regular Expression (with OR operators between subexpressions) to build a complex expression from each type.
By way of example, the following code is from the REXMLTypes constructor, which defines three expressions, with associated names and colors. The names are stored in the REXMLTypes class as constants (static final declarations).
addTokenType(COMMENT, ">!--.*-->;", Color.gray);
addTokenType(TAG, ">[^ ]*|[\\?]?>", Color.blue);
addTokenType(TEXT, ""(?:\\\\.|[^\"\\\\])*"", Color.red);
Explaining complex regular expressions is beyond the scope of this article but a few notes are worth highlighting. First, the order in which expressions are matched is the order in which they are declared, so when you use the addTokenType method, consider this important. Second, each expression that gets added using the addTokenType method becomes an alternative and we capitalize on the Java regular expression engine’s ability to use groups, as you’ll see in the RETokenizer code, to match tokens to their names. Finally, the expressions above may seem obscure but they are written to aggressively match suitable tokens.
The COMMENT type should be fairly obvious, matching any sequence of characters (the dot star means any number of any character) between the comment delimiter strings. The TAG expression is written to match tag elements so that leading or trailing angle brackets are picked up, the tag itself but not the attributes are captured, as well as optional closing slashes. The TEXT expression is concerned with quoted strings. I’ll refer you to the O’Reily “Mastering Regular Expressions” book for details on the gymnastics involved in avoiding false negatives and positives when working with quoted text sequences. Suffice it to say that these expressions can do the job and that they are easier to work with than might appear at first glance.
To get back to the RETokenizer code, our constructor expects an RETypes object and a text String. we use the RETypes’s getMatcher method to retrieved a Java regular expression Matcher object to do the actual tokenizing. The nextToken method does the work. It should be called for each token until it returns a null value. Again, we use an inner class to contain token details. The RETokenizer.Token class contains the text for a given token, the name of the token, taken from the RETypes names, and the position in the text to find the token beginning.
You’ll notice that we use a getToken method to figure out which type of token we are dealing with. The Java Matcher will return the same token we found if we ask for it with the right group number. In our XML example above, the group number for comments is one. We loop through the available groups until we find the token and then report the name by looking up the offset in the RETypes list. The getToken method creates a Token instance with the name, type and position in the text and returns it to be passed back as a return value for nextToken. As you can see, if there is no matching group for a given token, the value returned is null, though this should never actually happen.
Listing 2 shows the code for EditorDocument, which uses the Swing text infrastructure to manage text editing. The two key methods are insertString and remove, which are called any time the end user types new content or deletes any text. In both cases, we make sure the superclass handles all the bookkeeping and then call the highlightSyntax method to actually highlight the text. You’ll notice that the constructor sets a default style and stores a reference to an RETypes object before invoking the KeywordManager. I’ve made no attempt to separate keyword lists by RETypes, they are simply included in a keywords subdirectory and applied. You might want to move this code into subclasses and do this by document type in a real application.
The highlightSyntax method gets a reference to the text for the entire document and clears all styles before highlighting, so this approach will apply best to documents that have no styles that need to be preserved. If they did, your solution would have to be more elaborate. Fortunately, source code and XML documents are not normally styled documents, so this won’t matter most of the time. We create an instance of an RETokenizer and call nextToken repeatedly after that.
For each token we figure out the type and get the assigned color from the RETypes list. If no color is assigned (it returns null), we use the KeywordManager to decide what color to use for a token. The REJavaTypes class defines the ATOM expression as colorless, to make this strategy workable. In either case, we call the setCharacterAttributes method to set the Style for the token. The styles, are created by the RETypes method setStyles, which is called in our constructor. Once they are defined in the EditorDocument, we can look them up by name by using the getStyle method. The setCharacterAttributes method uses the pos offset from the Token, along with the token text’s length to set the style for a specified region of the document text. Since we clear all styles before starting the loop, the last argument tells the setCharacterAttributes method not to bother clear other contained styles before applying the new one.
Handling styled documents is a fairly straight forward endeavor when you know what you’re doing. With the power of regular expressions available in Java 1.4, we can now build sophisticated tokenizers that can find a wide variety of tokens with relative ease. Virtually any document can be broken into suitable elements for highlighting and the Style mechanism in Swing’s text documents is more than capable of handling the job. While this implementation is not optimally efficient, you can see from the code that the next step is not likely to be very complicated. I hope you’ve learned as much as I did from this implementation.
Listing 1
import java.util.*;
import java.util.regex.*;
public class RETokenizer
{
protected RETypes types;
protected Matcher matcher;
public RETokenizer(RETypes types, String text)
{
this.types = types;
matcher = types.getMatcher(text);
}
protected Token getToken(int pos)
{
int count = types.getTypeCount();
for (int i = 1; i <= count; i++)
{
String token = matcher.group(i);
if (token != null)
{
String type = types.getName(i - 1);
return new Token(token, type, pos);
}
}
return null;
}
public Token nextToken()
{
if (matcher.find())
{
return getToken(matcher.start());
}
return null;
}
public static class Token
{
public String token;
public String type;
protected int pos;
public Token(String token, String type, int pos)
{
this.token = token;
this.type = type;
this.pos = pos;
}
public String getText()
{
return token;
}
public String getType()
{
return type;
}
public int getPos()
{
return pos;
}
public String toString()
{
return type + "(" + token + ", " + pos + ')';
}
}
}
Listing 2
import java.awt.*;
import javax.swing.text.*;
public class EditorDocument
extends DefaultStyledDocument
{
protected RETypes types;
public EditorDocument(RETypes types)
{
Style defaultStyle = getStyle("default");
StyleConstants.setFontFamily(
defaultStyle, "Courier New");
StyleConstants.setFontSize(defaultStyle, 12);
this.types = types;
types.setStyles(this);
KeywordManager.setStyles(this);
}
public void insertString(int offset,
String text, AttributeSet style)
throws BadLocationException
{
super.insertString(offset, text, style);
highlightSyntax();
}
public void remove(int offset, int length)
throws BadLocationException
{
super.remove(offset, length);
highlightSyntax();
}
public void highlightSyntax()
{
try
{
String text = getText(0, getLength());
setCharacterAttributes(0, getLength(),
getStyle("default"), true);
RETokenizer.Token token;
RETokenizer tokenizer = new RETokenizer(types, text);
int typeCount = types.getTypeCount();
while ((token = tokenizer.nextToken()) != null)
{
int pos = token.getPos();
String type = token.getType();
String word = token.getText();
int len = word.length();
for (int i = 0; i < typeCount; i++)
{
String name = types.getName(i);
if (type.equals(name))
{
if (types.getColor(i) == null)
{
String style = KeywordManager.getStyleName(word);
if (style != null)
{
setCharacterAttributes(
pos, len, getStyle(style), false);
}
}
else
{
setCharacterAttributes(
pos, len, getStyle(name), false);
}
}
}
}
}
catch (Exception e)
{
e.printStackTrace();
}
}
}