
ORIGINAL DRAFT
When you write user interfaces, you inevitably have to collect information from text fields, validating the data before using it. There are several ways of handling validation. You can verify the text as the user exits the field by watching for lost focus events, or wait for them to dismiss a window or dialog box by pressing a button, validating all the fields at once. Both of these approaches are useful but can also lead to complex scenarios. Providing appropriate feedback and cursor positioning when invalid data gets entered can often become complicated.
Frequently, a better approach is to validate the information on-the-fly, as it’s being entered by the user, a technique known as keystroke validation. This month’s JMaskField goes much further than restricting the user to valid keystrokes, supporting the following advanced features:
- Customizable Rules: We use a regular expression-style syntax to define rules which determine whether a given character is acceptable for each position in the field. A mask can be defined with a mix of literal characters and validation rules.
- Macro Characters: We make it possible to associate any character with an expression in order to support a more compact notation. For example, the ‘#’ might be assigned to an expression like “[0-9]” to represent numerical values.
- Cursor Positioning: The cursor is positioned intelligently after keystrokes, skipping literal characters that do not need to be typed in by the user.
- Template Character: You can define any character as a visual cue to indicate positions where the user has not yet typed or where a character was deleted. The default template character is the underscore (‘_’).
Figure 1 shows the classes we’ll be developing and how they relate to each other. While this may seem like a lot, you can see by the diagram that most of the classes address tokenizing and parsing the mask. Once parsed, the validation is pretty straight forward and handled by our extension to the PlainDocument class. JMaskField extends JTextField and merely adds some cursor movement code to make it more user-friendly.
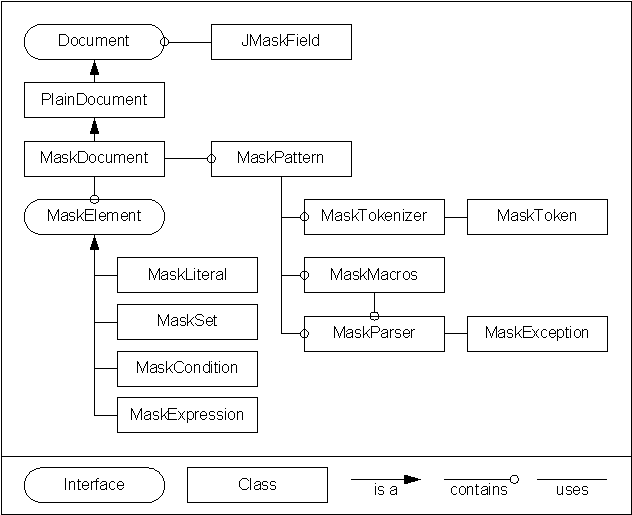
Figure 1: JMaskField Classes.
JMaskField provides the high-level interface you’ll use in your applications. In practice, you can provide a mask and template character in the JMaskField constructor and check the field output for template characters to determine if they were fully entered by the user at runtime.
Tokenizing Masks
To process the field mask, we need to tokenize the text and build a parse tree from the token list. The parse tree elements are used to match the characters as they are being typed by the user. The Java class library includes two out-of-the-box tokenizers: StringTokenizer and StreamTokenizer. While these are both useful, they don’t provide sufficient information to tell the user where problems occur, so we’ll create a more flexible solution.
The MaskTokenizer produces a list of MaskToken elements. The MaskToken class, in Listing 1, has two member variables
- pos, an integer value that stores the offset from the beginning of the tokenized text, and text, a string value storing the actual token. Because many tokens are single characters, we overload the equals method to handle both string and char inputs. This makes parsing easier when we need to determine what type of token we are dealing with.
Listing 2 shows the MaskTokenizer class, which has a single constructor that requires two arguments - an include string, identifying all delimiter characters which should be returned as tokens, and an exclude string, identifying all delimiter characters which should not be returned as tokens. A math tokenizer, for example, might use an include string like “+-*/” and an exclude string like “ “. This would return any non-space sequence and consider the math operators separate tokens.
The MaskTokenizer provides hasMoreTokens and nextToken methods, just like the Java tokenizers, but nextToken returns a MaskToken instance. In addition, we provide an ignoreToken method to push back the current position after reading a token. This is useful with most parsers, which sometimes need to look ahead before determining whether the next token is relevant.
Regular Expressions
Regular expressions are used heavily in languages like Perl and AWK and often applied by programmers either through command line searching with the GREP utility or in flexible search/find capabilities exposed in modern user interfaces. While these are often considered too complicated for average computer users, they fit quite nicely into the savvy programmer’s bag of tricks.
Table 1 lists the characters we’re interested in. Regular expressions have a couple of reserved characters that represent the beginning and end of a line as well as sequence modifiers. These are not directly applicable to our solution, so they are not included in this table. If you’re familiar with regular expressions, you’ll notice that we’ve changed the character for NOT operators. This is nothing more than artistic licence. Naturally, you’re free to change it to whatever you like if you prefer something else in your application.
| Character | Description |
| () | Precedence delimiters |
| [] | Character set delimiters |
| - | Set range delimiter |
| ! | NOT prefix operator |
| & | AND operator |
| | | OR operator |
| Any other character | Character literal |
We’ll take a look at the syntax in a moment. In the JMaskField widget, a mask is provided in the form of a string. The string can be a mix of literal characters, which may not be edited, and rules expressed using our regular expressions subset. To distinguish between rules and literals, we delimit rules with curly braces. Table 2 shows a few valid masks with a brief explanation for each.
| Mask | Description |
| "{[A-Z]}{[a-z]}{[a-z]}{[a-z]}" | One uppercase and three lowercased letters |
| "{[!0-9]} {[!0-9]} {[!0-9]}" | Any three non-numerical characters, separate by spaces |
| "{[02468]}{[13579]}" | Any even number followed by an odd number. |
| "(###) ###-####" | A phone number when macro '#' is defined as "[0-9]" |
The last example shows how macros can be used to make this syntax more compact. Lets take a quick look at the parser.
Parsing the Rules
Once the text has been tokenized, we can organize it by constructing a parse tree. When errors are encountered, we throw a MaskException, shows in Listing 3, to tells the caller what was expected and the text position where the error occurred. This makes it a lot easier to deal with syntax errors before they become a problem. The text offset position is especially informative and makes addressing any occurring problems much easier.
The rule parser uses several supporting classes to represent the resulting item list. Each of these implements the MaskElement interface from Listing 4, which enforces the use of a toString and a match method. The toString method is useful for debugging, so we can see the structure by just writing it out. The match method tests a character for validity and gets used in the document class we’ll implement later.
Here’s a quick look at the syntax using the BNF format:
<element> ::= '{' <condition> '}' | <literal>
<condition> ::= <expression> [ <conjunction> <condition> ]
<conjunction> ::= '&' | '|'
<expression> ::= '(' <expression> ')' | <character-set>
<character-set> ::= '[' [ '!' ] <characters-list> ']'
BNF allows us to represent the syntax in a manner which is very close to the way we need to program the parser. The productions above can be described in English very easily. Each production involves an element on the left and options on the right. In BNF, the options are separated by a ‘|’ character and may include optional elements, delimited by square brackets. Thus, the first productions means an element is either a condition (delimited by curly braces) or a literal.
The second production means a condition is an expression, followed by an optional conjunction and another condition. The conjunctions are either the or (‘|’) or the and (‘&’) character. The expression production is primarily there to allow parenthesis-delimited nesting, exactly the way mathematical expressions can be given precedence by wrapping them in parentheses. If no parenthesis is present, we expect a character set.
We consider a character set to be a special case in our parser, expecting a set to be delimited by square brackets and to be optionally negated, using the ‘!’ modifier. Character ranges are not handled as tokenized elements. It’s easier to consider anything tokenized as a single character sequence and to process sets with the parser. When we run into a set, we traverse the characters and handle dash (‘-‘) delimited character pairs by dynamically expanding them so that the resulting set is explicit. This makes later matching more efficient.
Listing 5 shows the MaskLiteral class, which represents literals and stores the character internally. The match method simply does a direct comparison with the test character. Macro characters are considered literals until they are interpreted at runtime. This allows us to change the macro definitions without requiring the mask to be parsed again, increasing our flexibility.
The MaskSet class is shown in Listing 6. A set of characters is made explicit by the parser, expanding hyphenated ranges into a string list. The parser automatically handles inverted ranges if the value of the rightmost character is less than the value of the leftmost character. The only additional information required in our MaskSet representation is the negation marker if a NOT operator was used, stored as a boolean value.
Listing 7 shows the MaskExpression class. Expressions are just wrappers designed to handle precedence. The match method calls the encapsulated MaskElement at comparison time. MaskCondition is more interesting. Listing 8 shows how it stores a boolean value to indicate whether an AND or OR conjunction is used. We keep a couple of constants around to make the parser code more readable. The match method uses the Java logical AND (‘&’) and OR (‘|’) operators to resolve the function. The left and right arguments are resolved by calling their own match methods.
The MaskParser, shown in Listing 9, is implemented as a separate class so it can be used by both the MaskMacros and MaskDocument classes. There isn’t enough room here to say very much about recursive decent parsers, other than the fact that they operate much as the name implies, using recursion to build a tree structure, descending to parse any nested structures. As mentioned earlier, the structure of the methods in MaskParser closely resemble the structure of the BNF notation used to represent the syntax.
Extending the Model
One of the objectives I had when I decided to implement the JMaskField control was to make it both powerful and easy to use. This is one of those standard programming dichotomies which is difficult to resolve and requires some thought. The best option I was able to identify was to make the syntax for defining rules ultimately flexible to make it powerful, providing a mechanism for abstracting those rules in simple form. This mechanism is implemented in the form of character macros.
Figure 2 shows how a simple mask gets expanded to a parsed expression, and finally to explicit character sets.
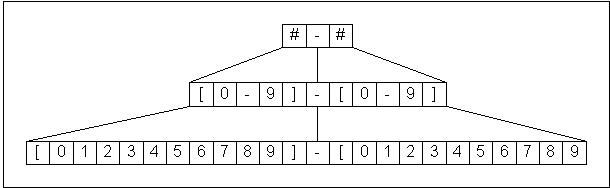
Figure 2: Mask Expansion.
Listing 10 shows how the MaskMacro class is really little more than a Hashtable that stores an association between a given character and a MaskElement representing the rule(s) to be applied. When the MaskDocument in Listing 11 runs into a character literal, it checks to see if there is a rule associated with it in the MaskMacro model. While it is always possible to define masks by using the curly brace syntax, you can see that it’s much easier to define your own rules and assign them to macro characters.
The Document Model
The MaskDocument class extends the PlainDocument class in the JFC and can be assigned to any JTextComponent. The JMaskField class is presented in Listing 12 and extends JTextField, implementing additional behavior to handle intelligent cursor movement. Lets take a quick look at the MaskDocument class before we cover the JMaskField code.
To provide visual feedback, we generate a template for the mask expression. To keep things simple for the user, we’ll be using an underscore as a place-holder for non-literal characters. The underscore is the default template character, but you can change it easily if you prefer something else. Figure 3 shows how the mask, presentation and user input parallel each other.
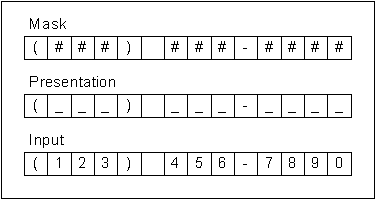
Figure 3: Mask Presentation.
The MaskDocument class implements supporting methods to handle the template and to make character matching easier but it primarily implements the remove and insertString methods required by the JFC Document interface. The Document interface has two methods which we have to override in order to get the behavior we need.
- void insertString(int pos, String text, AttributeSet attr);
- void remove(int pos, int length);
The insertString method is called anytime new data is entered in the text field, typically after every keystroke. The remove method is called whenever text is deleted.
The insertString and remove methods can pass several characters at the same time, as would be the case in cut or paste operations. To support these, we break each string into single characters and handle them recursively. The net effect is that a parse operation may not complete if some of the characters don’t match, but the field will still handle as many characters as possible. Each character, processed individually, is tested by the match method and allowed to replace template characters in the insertString method. A character is replaced by a template character when being deleted in the remove method.
Summary
Figure 4 shows JMaskField in action. The Phone and Postal Code fields have already been entered and the other fields demonstrate a mix of literal and template characters that provide visual cues to guide the user through a successful experience. When inappropriate characters are typed in, the user hears a beep and the character is rejected.
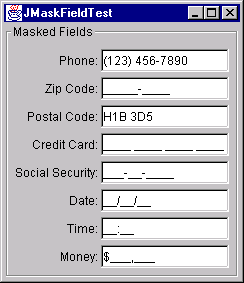
Figure 4: JMaskField at Work.
JMaskField provides a flexible mechanism for constraining character entries in a text field. Because it uses standard Java strings, any valid character pattern can be applied to define the data mask. The simple regular expression-like syntax lets you define arbitrary character rules. Extending this model to support character macros adds even more flexibility and the template view provides useful feedback for the user. Together, these elements provide you with yet another tool to make the user experience as pleasant as possible. Use it in good health.
Listing 1
public class MaskToken
{
protected int pos;
protected String text;
public MaskToken(int pos, String text)
{
this.pos = pos;
this.text = text;
}
public boolean equals(char chr)
{
if (text.length() == 1)
return chr == text.charAt(0);
else return false;
}
public boolean equals(String test)
{
return text.equals(test);
}
public String toString()
{
return "token(" + pos + "," + '"' + text + '"' + ")";
}
}
Listing 2
public class MaskTokenizer
{
protected Vector tokens = new Vector();
protected String include, exclude;
protected int pos = 0;
public MaskTokenizer(String include, String exclude)
{
this.include = include;
this.exclude = exclude;
}
public void tokenize(String text)
{
int prev = 0;
tokens.removeAllElements();
StringBuffer buffer = new StringBuffer();
for (int i = 0; i < text.length(); i++)
{
if (include.indexOf(text.charAt(i)) > -1)
{
if (buffer.length() > 0) tokens.addElement(
new MaskToken(prev, buffer.toString()));
tokens.addElement(
new MaskToken(i, "" + text.charAt(i)));
buffer.setLength(0);
prev = i + 1;
}
else if (exclude.indexOf(text.charAt(i)) > -1)
{
if (buffer.length() > 0) tokens.addElement(
new MaskToken(prev, buffer.toString()));
buffer.setLength(0);
prev = i + 1;
}
else buffer.append(text.charAt(i));
}
if (buffer.length() > 0) tokens.addElement(
new MaskToken(prev, buffer.toString()));
}
public boolean hasMoreTokens()
{
return pos < tokens.size();
}
public MaskToken nextToken()
{
return (MaskToken)tokens.elementAt(pos++);
}
public void ignoreToken()
{
if (pos > 0) pos--;
}
}
Listing 3
public class MaskException extends RuntimeException
{
public MaskException(String description)
{
super(description);
}
}
Listing 4
public interface MaskElement
{
public String toString();
public boolean match(char chr);
}
Listing 5
public class MaskLiteral implements MaskElement
{
protected char chr;
public MaskLiteral(char chr)
{
this.chr = chr;
}
public String toString()
{
return "literal('" + chr + "')";
}
public boolean match(char chr)
{
return this.chr == chr;
}
}
Listing 6
public class MaskSet implements MaskElement
{
protected boolean negate;
protected String set;
public MaskSet(boolean negate, String set)
{
this.negate = negate;
this.set = set;
}
public String toString()
{
return (negate ? "not(" : "set(") + set + ")";
}
public boolean match(char chr)
{
boolean member = set.indexOf(chr) > -1;
if (negate) return !member;
else return member;
}
}
Listing 7
public class MaskExpression implements MaskElement
{
protected MaskElement element;
public MaskExpression(MaskElement element)
{
this.element = element;
}
public String toString()
{
return "expression(" + element.toString() + ")";
}
public boolean match(char chr)
{
return element.match(chr);
}
}
Listing 8
public class MaskCondition implements MaskElement
{
public static final boolean AND = true;
public static final boolean OR = false;
protected boolean and;
protected MaskElement left, right;
public MaskCondition(boolean and,
MaskElement left, MaskElement right)
{
this.and = and;
this.left = left;
this.right = right;
}
public String toString()
{
return "rule(" + left.toString() +
(and ? " and " : " or ") +
right.toString() + ")";
}
public boolean match(char chr)
{
if (and) return left.match(chr) && right.match(chr);
else return left.match(chr) || right.match(chr);
}
}
Listing 9
public class MaskParser
{
public MaskElement parseMacro(String text)
{
MaskTokenizer tokenizer =
new MaskTokenizer("&|![]() ", "");
tokenizer.tokenize(text);
return parseCondition(tokenizer);
}
public MaskElement parseCondition(MaskTokenizer tokenizer)
{
MaskElement node = parseExpression(tokenizer);
if (tokenizer.hasMoreTokens())
{
MaskToken next = tokenizer.nextToken();
if (next.equals('|'))
{
return new MaskCondition(MaskCondition.OR,
node, parseCondition(tokenizer));
}
if (next.equals('&'))
{
return new MaskCondition(MaskCondition.AND,
node, parseCondition(tokenizer));
}
}
tokenizer.ignoreToken();
return node;
}
private MaskElement parseExpression(MaskTokenizer tokenizer)
{
MaskToken token = tokenizer.nextToken();
if (token.equals('('))
{
MaskElement node = parseCondition(tokenizer);
expect(tokenizer.nextToken(), ')');
return new MaskExpression(node);
}
tokenizer.ignoreToken();
return parseSet(tokenizer);
}
private MaskElement parseSet(MaskTokenizer tokenizer)
{
expect(tokenizer.nextToken(), '[');
MaskToken token = tokenizer.nextToken();
boolean negate = token.equals('!');
if (negate) token = tokenizer.nextToken();
expect(tokenizer.nextToken(), ']');
return new MaskSet(negate, expandSet(token.text));
}
private String expandSet(String text)
{
int i = 0;
StringBuffer buffer = new StringBuffer();
while (i < text.length())
{
if (i < text.length() - 2 && text.charAt(i + 1) == '-')
{
int from = (int)text.charAt(i);
int to = (int)text.charAt(i + 2);
if (from > to)
{
int temp = from;
from = to;
to = temp;
}
for (int c = from; c <= to; c++)
{
buffer.append((char)c);
}
i += 3;
}
else
{
buffer.append(text.charAt(i));
i++;
}
}
return buffer.toString();
}
public static void expect(MaskToken token, char chr)
{
if (!token.equals(chr)) throw new MaskException(
"Syntax error: '" + chr + "' expected at " + token.pos);
}
}
Listing 10
public class MaskMacros
{
protected Hashtable table;
protected MaskParser parser = new MaskParser();
public MaskMacros()
{
table = new Hashtable();
}
public void addMacro(char key, String macro)
{
MaskElement element = parser.parseMacro(macro);
table.put(new Character(key), element);
}
public void removeMacro(char key)
{
table.remove(new Character(key));
}
public MaskElement getMacro(char key)
{
return (MaskElement)table.get(new Character(key));
}
public boolean containsMacro(char key)
{
return table.containsKey(new Character(key));
}
public String toString()
{
StringBuffer buffer = new StringBuffer();
buffer.append("macros\n{\n");
Enumeration keys = table.keys();
Enumeration enum = table.elements();
Character key;
MaskElement element;
while (keys.hasMoreElements())
{
key = (Character)keys.nextElement();
element = (MaskElement)enum.nextElement();
buffer.append(" " + key.charValue() + "=");
buffer.append(element.toString() + "\n");
}
buffer.append("}\n");
return buffer.toString();
}
}
Listing 11
public class MaskDocument extends PlainDocument
{
protected char templateChar;
protected MaskMacros macros;
protected MaskTokenizer tokenizer;
protected Vector pattern = new Vector();
protected MaskParser parser = new MaskParser();
public MaskDocument(String mask,
MaskMacros macros, char templateChar)
{
this.templateChar = templateChar;
this.macros = macros;
parse(mask);
}
public void parse(String text)
{
MaskTokenizer tokenizer =
new MaskTokenizer("&|![](){} ", "");
pattern.removeAllElements();
tokenizer.tokenize(text);
while (tokenizer.hasMoreTokens())
{
parseElement(tokenizer);
}
}
private void parseElement(MaskTokenizer tokenizer)
{
MaskToken next = tokenizer.nextToken();
if (next.equals('{'))
{
pattern.addElement(parser.parseCondition(tokenizer));
MaskParser.expect(tokenizer.nextToken(), '}');
}
else
{
String text = next.text;
for (int i = 0; i < text.length(); i++)
{
pattern.addElement(new MaskLiteral(text.charAt(i)));
}
}
}
public MaskElement getRule(int index)
{
return (MaskElement)pattern.elementAt(index);
}
public String template()
{
int length = pattern.size();
StringBuffer buffer = new StringBuffer();
for (int i = 0; i < length; i++)
{
buffer.append(template(i));
}
return buffer.toString();
}
public char template(int pos)
{
MaskElement rule = getRule(pos);
if (rule instanceof MaskLiteral)
{
char literal = ((MaskLiteral)rule).chr;
if (!macros.containsMacro(literal))
return literal;
}
return templateChar;
}
public boolean match(int pos, char chr)
{
MaskElement element = getRule(pos);
if (element instanceof MaskLiteral)
{
char macro = ((MaskLiteral)element).chr;
if (macros.containsMacro(macro))
{
return macros.getMacro(macro).match(chr);
}
}
return element.match(chr);
}
public void insertString(int pos, String text,
AttributeSet attr) throws BadLocationException
{
int len = text.length();
if (len == 0) return;
if (len > 1)
{
for (int i = pos; i < len; i++)
insertString(pos, "" + text.charAt(i), attr);
return;
}
else
{
if (match(pos, text.charAt(0)))
{
super.remove(pos, 1);
super.insertString(pos, text, attr);
}
else
{
Toolkit.getDefaultToolkit().beep();
return;
}
}
}
public void remove(int pos, int length)
throws BadLocationException
{
if (length > 1)
{
for (int i = pos; i < length; i++)
remove(pos, 1);
return;
}
else
{
if (length == 0 && getLength() == 0)
{
String template = template();
super.insertString(pos, template, null);
return;
}
if (pos == getLength()) return;
String text = "" + template(pos);
super.remove(pos, 1);
super.insertString(pos, text, null);
}
}
}
Listing 12
public class JMaskField extends JTextField implements
DocumentListener, KeyListener, FocusListener
{
protected MaskMacros macros;
protected MaskDocument doc;
protected boolean bspace;
protected boolean delete;
protected int pos = -1;
public JMaskField(String mask)
{
this(mask, new MaskMacros(), '_');
}
public JMaskField(String mask, MaskMacros macros)
{
this(mask, macros, '_');
}
public JMaskField(String mask,
MaskMacros macros, char templateChar)
{
setMacros(macros);
doc = new MaskDocument(mask, macros, templateChar);
doc.addDocumentListener(this);
addFocusListener(this);
addKeyListener(this);
setDocument(doc);
setText("");
setPreferredSize(new Dimension(128, 23));
}
public MaskMacros getMacros()
{
return macros;
}
public void setMacros(MaskMacros macros)
{
this.macros = macros;
}
private void adjustCaretForward(int pos)
{
while (isLiteral(pos)) {pos++;}
if (pos > doc.getLength()) pos = doc.getLength();
setCaretPosition(pos);
}
private void adjustCaretBackward(int pos)
{
while (isLiteral(pos - 1)) {pos--;}
if (pos <= 0)
{
adjustCaretForward(0);
}
else setCaretPosition(pos);
}
private boolean isLiteral(int pos)
{
if (pos < 0 || pos >= doc.pattern.size())
return false;
MaskElement rule = doc.getRule(pos);
if (rule instanceof MaskLiteral)
{
char literal = (((MaskLiteral)rule).chr);
return !doc.macros.containsMacro(literal);
}
return false;
}
public void focusLost(FocusEvent event)
{
pos = getCaretPosition();
}
public void focusGained(FocusEvent event)
{
if (pos < 0) adjustCaretForward(0);
else setCaretPosition(pos);
}
public void keyTyped(KeyEvent event) {}
public void keyReleased(KeyEvent event) {}
public void keyPressed(KeyEvent event)
{
bspace = event.getKeyCode() == KeyEvent.VK_BACK_SPACE;
delete = event.getKeyCode() == KeyEvent.VK_DELETE;
}
public void changedUpdate(DocumentEvent event) {}
public void removeUpdate(DocumentEvent event) {}
public void insertUpdate(DocumentEvent event)
{
int pos = event.getOffset();
int len = event.getLength();
if (bspace) adjustCaretBackward(pos);
else if (delete) setCaretPosition(pos);
else adjustCaretForward(pos + 1);
}
}