
ORIGINAL DRAFT
Many applications make use of sophisticated string-matching algorithms, but Java doesn’t include an interface designed explicitly for this purpose. This article centers on a simple pattern-matching interface. We’ll implement a set of classes that use this interface for string matching. In the process, we’ll be building a few classes for imprecise matching (Alike and Soundex), as well as an OS-style Wildcard implementation and more sophisticated RegularExpression classes. We’ll finish up with a set of FilenameFilter classes to demonstrate at least one practical use for the interface.
A lot of regular expression implementations have been developed in Java. Some use nothing but inline code, making poor use of object-oriented design. Others use so many classes that the resulting implementation is difficult to manage. We’ll use a hybrid approach, using as few classes as possible while remaining object-oriented by design, resulting in a nice, thin, fast and readable implementation that does the job without undue complexity. The implementation is complete and uses the Match interface to maximize reusability.
While Java provides idioms for handling equality (the equals method) and other patterns for dealing with comparison (the Comparable and related interfaces in the Collections API), none of these are designed explicitly for pattern-matching. What we need is something simple that can help define a contract between pattern-matching algorithms and the classes that use them. We’ll use a new interface called Match, which looks like this:
public interface Match
{
public boolean match(String text);
}
Figure 1 shows the relationship between this interface and the concrete classes we’ll implement.
Figure 1: Match classes. Each of the concrete classes implement the Match interface.
Listing 1 shows the Wildcard implementation, which implements the Match interface and allows us to test any string with the match method. All we need to do is create an instance with the wildcard pattern that we want to test. We can then call the match method and it will return true if the match is valid. Naturally, you can create as many instances of Wildcard as you like, each with a different pattern to match. Let’s take a quick run through the code.
The constructors allows us to store the pattern we’re interested in matching, along with a windows flag that determines whether we consider the "." pattern a match for everything. This is only important in Windows when you are looking at file names. There are two implementations of the match method in this class. The first implements the Match interface. The second does the real work and is implemented recursively. It first tests for a zero-length pattern or text input. If the wildcard pattern length is zero, we assume this is a match. If the test string length is zero, we assume there is no match. We also test for the "." pattern if the windows boolean value is true.
The rest of the algorithm walks through each character, testing for equality. When we run into a ‘?’ character in the pattern, we simply increment the position counter and consider it a match. The recursive code deals with the ‘*’ character by checking the tail of the text string for a match. If we get to the end of the method and all characters have been accounted for in both the pattern and the text to be matched, we have succeeded and thus return true. Any failure along the way implies the match has failed.
You’ll find a class called Alike at www.java-pro.com, which implements an algorithm published by Hans G. Zwakenberg in the "C Users Journal" in May of 1991. The article was titled "Inexact Alphanumeric Comparisons". The algorithm uses a Levenstein Distance calculation to measure the distance between two strings and returns true if the value is lower than a given threshold. I’ll refer you to the original article for an explanation of the algorithm. This class implements the Match interface and is likely to be useful when you need to match strings on the basis of similarity.
Listing 2 shows the Soundex implementation, which uses a sound-alike algorithm to match similar-sounding text. Normally, only the first 4 characters are used and the algorithm is typically applied to single words. You could make this more open-ended by removing the substring call at the end of the encode method, though if you try to match long strings, you’ll probably get better results if you parse it and match one word at a time.The Soundex algorithm encodes a word/string by removing all non-alphabetical characters as well as adjacent character repetition, and then assigns a numerical value to each character. We merely need to compare the result for equality and see if we have a match.
Expressing Yourself
Let’s get to the more complex regular expression code. Some readers (and you know who you are) are interested in that code more than anything else in this article. I can’t blame you for that given that many of the published implementations are incomplete or more complicated than they need to be. Let’s address design the choices I made in this regular expression implementation.
I’ve actually written a number of regular expression variants in the last few years and there are two extremes which come up regularly. The first is what I’ll call the inline code problem, which tries to mimic the way C code implementations handle regular expressions. The problem with that approach is that the code in difficult to read and maintain, and it tends to make poor use of any object-oriented benefits you might gain. The other extreme makes everything an object and results in close to a dozen classes that need to be maintained individually, again resulting in a difficult to read and manage code base.
Our implementation uses an object oriented design, but aspires to a minimalist approach that keeps the number of classes constrained. In fact, because these classes are only used internally, they’ll be implemented as inner classes in the RegularExpression class. Our compromise is simple. For terminal elements we use a single Terminal class that stores the actual token. The pure object-oriented approach would use a separate class for each of the terminal elements types and would result in three classes. We get similar savings by combining different types of groupings, cutting the total number of classes down to about half, without sacrificing anything important. We get the benefits of an object-oriented approach, without the high overhead.
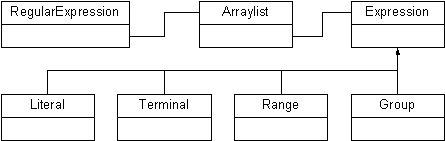
Figure 2: RegularExpression Classes. The ArrayList contains Expression instances of different types.
If you’ve never looked at a regular expression implementation before, some things require explanation. There are three terminal characters, for example, to mark the beginning and end of a line, as well as a single character wildcard. These are generally called BOL (Beginning Of Line), EOL (End Of Line) and ANY (match any character). These are represented by the characters ‘^’, ‘$’ and ‘.", respectively. Regular expressions also support groups of characters which can be any number of literal characters or ranges between square brackets. The opening and closing square brackets are named BOC (Beginning Of Class) and EOC (End Of Class), respectively. Finally, there are three modifiers that let you handle optionally and pattern repetition. These are the MORE (‘*’ - zero or more), MANY (‘+’ - one or more) and OPT (‘?’ optional) modifiers. The only other variant is the BOL (‘^’) character, which can be used to negate (invert the logic as with a NOT operator) an expression when used as the first character inside square brackets.
Most regular expression implementations store an internal representation of the pattern for optimization reasons. For example, it’s much faster to expand a range (a class) of characters into a string and then do a character membership test than it is to interpret the range information on-the-fly every time. We’ll be storing our internal representation as classes in an ArrayList. When the constructor is passed a pattern string, we parse it into this list and use this list later to test whether we have a match or not.
Listing 3 shows the code for the RegularExpression class. In this file, you’ll find 5 inner classes. The first class is merely an abstract class called Expression, which defines a test method we’ll use to do matching tests on each element. Notice that we pass it a StringBuffer rather than a String because we have to remove characters as we go AND return a boolean value indicating whether we were successful or not. Any test that returns false means the whole match attempt failed, but a success requires that we remove the part that actually matched so that subsequent tests can start at the beginning of the string buffer.
We could have kept a counter or done string reassignment to accommodate the same requirement, but the implementation would have been more complicated by virtue of having to maintain unscoped instance variables or by having to return compound result objects containing a boolean, string and/or position from each test. This implementation is faster because additional objects don’t need to be created. The code is also much easier to read and maintain.
Each of the inner classes extend the Expression class, implementing different elements of the same type. The Literal object captures a single literal character and the test returns true if there is an exact match of the first character in the string buffer, in which case the character is removed from the buffer. You’ll notice that each of the Expression subclasses also implement the toString method which allows us to print the output list in a readable manner for debugging purposes.
The Terminal inner class is also quite simple and represents one of the BOL, EOL or MORE elements. The test method returns true if we’re testing for an EOL (End of Line) and the buffer is empty or if we match any character (with ANY). The test for BOF (Beginning of Line) is actually done when we start matching, so we ignore it in this class.
The Range class is there to capture the semantics of a range of characters. This is formally called a class, but naming it that way would conflict with the Java naming restrictions, so I decided that Range was a suitably reflective name. There is some parsing code in this class which deals with a possible negation operator (‘^’) and any number of single character or hyphenated character pairs, watching for the EOC (End of Class) marker. The result is built up as an explicit string of characters which are easy to test for with the String.indexOf method. The test is made considerably faster by the pre-processing we do during parsing.
The final inner class captures the notion of a Group, which can be zero, one or more repeated patterns. The test method reflects this by supporting repeated loops for the MORE and MANY variants, enforcing at least one occurrence of the pattern in the MANY case. The OPT (optional) case processes the pattern test but ignores the boolean result. If there is a match, the pattern test will properly remove the match from the string buffer, so we don’t care what happens either way.
Goodies
As I mentioned earlier, you’ll find several classes online that are not here in print. Among them are a set of implementations that use the Match interface in a FilenameFilter. The class hierarchy is shown in Figure 3.
Figure 3: FilenameFilter implementations.
The MatchFilter class in Listing 4 provides most of the functionality. It implements the Java FilenameFilter interface and uses our Match interface to create a flexible way of selecting files or directories. The class contains a number of constants that let you decide whether file names, directory names or both will be tested for a match. By default, the assumption is that you are interested in files. This class is especially useful in combination with Wildcard implementation, but you’re not constrained to a particular filter type. When you download the code, you’ll FilenameFilter classes for each of the concrete Match implementations we’ve developed.
Of course, you are not limited to FilenameFilter implementations. For example, you could write specialized Iterator implementations that remove elements that match or don’t match in a List with using the Collections API, or you can provide search capabilities in Swing JText-related components. I suspect you’ll find a few other uses and you can easily extend the paradigm with additional classes that implement the Match interface to suit your needs. Have fun with it.
Listing 1
public class Wildcard implements Match
{
public static final char ANY = '?'; // Any single character
public static final char MORE = '*'; // Zero or more characters
public static final String DOS = "*.*"; // Relevant under Windows
protected String pattern;
protected boolean windows;
public Wildcard(String pattern)
{
this(pattern, true);
}
public Wildcard(String pattern, boolean windows)
{
this.pattern = pattern;
this.windows = windows;
}
public boolean match(String text)
{
return match(pattern, text);
}
protected boolean match(String wild, String text)
{
if (wild.length() == 0) return true;
if (text.length() == 0) return false;
if (windows && wild.equalsIgnoreCase(DOS))
return true;
int j = 0;
for (int i = 0; i < wild.length(); i++)
{
if (j > text.length()) return false;
// We have a '?' wildcard, match any character
else if (wild.charAt(i) == ANY)
{
j++;
}
// We have a '*' wildcard, check for a match in the tail
else if (wild.charAt(i) == MORE)
{
for (int f = j; f < text.length(); f++)
{
if (match(wild.substring(i + 1), text.substring(f)))
return true;
}
return false;
}
// Both characters match, case insensitive
else if (j < text.length() &&
Character.toUpperCase(wild.charAt(i)) !=
Character.toUpperCase(text.charAt(j)))
{
return false;
}
else j++;
}
if (j == text.length()) return true;
else return false;
}
}
Listing 2
public class Soundex implements Match
{
protected String pattern;
public Soundex(String pattern)
{
this.pattern = encode(pattern);
}
public boolean match(String text)
{
return pattern.equals(encode(text));
}
public String encode(String input)
{
String text = input.toLowerCase();
for(int i = 0; i < input.length() - 1; i++)
{
char head = text.charAt(i);
if (head >= 'a' && head <= 'z')
{
String tail = input.substring(i + 1);
return head + phonetic(tail).substring(3);
}
}
return "";
}
private String phonetic(String input)
{
StringBuffer buffer = new StringBuffer();
// For each character, skipping adjacent duplicates
for(int i = 0; i < input.length() - 1; i++)
{
if (input.charAt(i) != input.charAt(i + 1))
{
char code = charCode(input.charAt(i));
// If soundex code is not zero, add to buffer
if (code != '0') buffer.append(code);
}
}
return buffer.toString();
}
private char charCode(char chr)
{
switch (chr)
{
case 'b': return '1';
case 'c': return '2';
case 'd': return '3';
case 'f': return '1';
case 'g': return '2';
case 'j': return '2';
case 'k': return '2';
case 'l': return '4';
case 'm': return '5';
case 'n': return '5';
case 'p': return '1';
case 'q': return '2';
case 'r': return '6';
case 's': return '2';
case 't': return '3';
case 'v': return '1';
case 'x': return '2';
case 'z': return '2';
default : return '0';
}
}
}
Listing 3
import java.util.*;
public class RegularExpression implements Match
{
public static final char BOL = '^'; // Beginning of line
public static final char EOL = '$'; // End of line
public static final char ANY = '.'; // Any single character
public static final char BOC = '['; // Start of class
public static final char EOC = ']'; // End of class
public static final char MORE = '*'; // Zero or more
public static final char MANY = '+'; // One or more
public static final char OPT = '?'; // Optional
protected ArrayList list; // Internal list of tokens
protected String pattern;
/**
* Constructor expects a regular expression pattern string which it
* immediately parses into components. The result is stored
* internally in the ArrayList and serves to later match against
* any required strings.
* @param pattern Any regular expression string desired.
**/
public RegularExpression(String pattern)
{
this.pattern = pattern;
list = new ArrayList();
StringBuffer buffer = new StringBuffer(pattern);
while (buffer.length() > 0)
{
parse(buffer);
}
}
/**
* Return the last element from the list and remove it at
* the same time. This is useful with the optional and repeating
* elements where the operation applies to the preceding element.
* The repeaters pop the list and make the value part of their
* definition, folding the item into their structures.
**/
private Expression pop()
{
return (Expression)list.remove(list.size() - 1);
}
/**
* Parse the next item, popping the characters off the work
* string on each iteration. The repeaters fold the previous
* item into their structures. The class range calls a method
* that makes the ranges of characters explicit for faster
* lookup during pattern matching.
**/
private void parse(StringBuffer buffer)
{
char ch = buffer.charAt(0);
buffer.deleteCharAt(0);
switch(ch)
{
case BOL: list.add(new Terminal(BOL)); break;
case EOL: list.add(new Terminal(EOL)); break;
case ANY: list.add(new Terminal(ANY)); break;
case MORE: list.add(new Group(MORE, pop())); break;
case MANY: list.add(new Group(MANY, pop())); break;
case OPT: list.add(new Group(OPT, pop())); break;
case BOC: list.add(new Range(buffer)); break;
default: list.add(new Literal(ch));
}
}
/**
* External call to be made if you want to check a string against
* the regular expression described by this object.
* @param text The text to compare with the regular expression.
* @return A boolean value indicating whether the string matches or not.
**/
public boolean match(String text)
{
StringBuffer buffer = new StringBuffer(text);
for (int i = 0; i < list.size(); i++)
{
if (buffer.length() == 0) return false;
Expression expression = (Expression)list.get(i);
if (expression instanceof Terminal &&
((Terminal)expression).type == BOL)
{
// BOL is only valid if this is the first element
if (i > 0) return false;
}
else if (!expression.test(buffer)) return false;
}
return true;
}
// ------------------------------------------------------------------
// Inner Support Classes
// ------------------------------------------------------------------
protected abstract class Expression
{
public abstract boolean test(StringBuffer buffer);
}
protected class Literal extends Expression
{
protected char token;
public Literal(char token)
{
this.token = token;
}
public boolean test(StringBuffer buffer)
{
char chr = buffer.charAt(0);
if (token == chr)
buffer.deleteCharAt(0);
return token == chr;
}
public String toString()
{
return "literal('" + token + "')";
}
}
protected class Terminal extends Expression
{
protected int type;
public Terminal(int type)
{
this.type = type;
}
public boolean test(StringBuffer buffer)
{
if (type == EOL)
{
return buffer.length() == 0;
}
if (type == ANY)
{
buffer.deleteCharAt(0);
return true;
}
return false;
}
public String toString()
{
String name = "any";
if (type == BOL) name = "bol";
if (type == EOL) name = "eol";
return name;
}
}
protected class Range extends Expression
{
protected String chars;
public Range(StringBuffer text)
{
chars = parse(text);
}
public boolean test(StringBuffer buffer)
{
boolean result;
char ch = buffer.charAt(0);
String temp = chars;
if (chars.charAt(0) == '^')
{
temp = temp.substring(1);
result = temp.indexOf(ch) < 0;
}
else
{
result = temp.indexOf(ch) > -1;
}
if (result)
buffer.deleteCharAt(0);
return result;
}
/**
* Parse multiple ranges with or without a preceding NOT
* operator. The NOT operator is a hardcoded '^' character.
* This call returns an explicit list of characters with all
* characters in the range in the string.
**/
protected String parse(StringBuffer buffer)
{
String range, total = "";
if (buffer.charAt(0) == '^')
{
buffer.deleteCharAt(0);
total = "^";
}
while ((range = parseRange(buffer)) != null)
{
total += range;
}
return total;
}
/**
* Parse a range in the form a-b where 'a' is the low value and
* 'b' is the high value, taking into account single character
* ranges (where no dash '-' or second value is involved).
* @return The string of explicit characters to match.
**/
protected String parseRange(StringBuffer buffer)
{
if (buffer.length() == 0) return null;
if (buffer.charAt(0) == EOC)
{
buffer.deleteCharAt(0);
return null;
}
char from, to;
if (buffer.charAt(1) == '-')
{
from = buffer.charAt(0);
to = buffer.charAt(2);
StringBuffer range = new StringBuffer();
for (char i = from; i <= to; i++)
{
range.append(i);
}
buffer.delete(0, 2);
return range.toString();
}
else
{
from = buffer.charAt(0);
buffer.deleteCharAt(0);
return "" + from;
}
}
public String toString()
{
return "class(" + '"' + chars + '"' + ")";
}
}
protected class Group extends Expression
{
protected int type;
protected Expression expr;
public Group(int type, Expression expr)
{
this.type = type;
this.expr = expr;
}
public boolean test(StringBuffer buffer)
{
if (type == OPT)
{
expr.test(buffer);
return true;
}
if (type == MORE)
{
while (expr.test(buffer)) {}
return true;
}
if (type == MANY)
{
if (!expr.test(buffer)) return false;
while (expr.test(buffer)) {}
return true;
}
return false;
}
public String toString()
{
String name = "optional";
if (type == MORE) name = "zeroormore";
if (type == MANY) name = "oneormore";
return name + "(" + expr + ")";
}
}
}
Listing 4
import java.io.*;
public class MatchFilter implements FilenameFilter
{
public static final int INCLUDE_FILE = 1;
public static final int INCLUDE_PATH = 2;
public static final int INCLUDE_BOTH = 3;
protected Match match;
protected boolean includeFile, includePath;
public MatchFilter(Match match)
{
this(match, INCLUDE_FILE);
}
public MatchFilter(Match match, int include)
{
this.match = match;
includeFile = ((include & INCLUDE_FILE) == INCLUDE_FILE);
includePath = ((include & INCLUDE_PATH) == INCLUDE_PATH);
}
public boolean accept(File dir, String name)
{
File file = new File(dir, name);
if (includeFile && !file.isFile())
return false;
if (includePath && !file.isDirectory())
return false;
return match.match(file.getName());
}
}