
ORIGINAL DRAFT
One of the more common needs of a web site designer is to provide a search capability for local content. There are a lot of ways you can do this, ranging from public domain Perl scripts to more sophisticated commercial solutions. When a friend of mine started looking for this kind of answer and asked about using Java, I was disappointed to see a lack of solutions and offered to help. This article reflects the work I did to develop a Java Servlet-based HTML search engine.
he design is based on a few simple requirements and propositions:
- The visual footprint should be minimal, both the query and the hit list should take up minimum html space.
- The solution can be implemented as a separate indexer and a search engine that runs against the generated index at runtime.
- The index will be plain text to keep things simple (avoiding the need for a database or a b-tree structure).
- An HTML parser will remove html tags and make the text content accessible for indexing.
- The search engine will support boolean AND and OR operators. OR is implied if nothing is specified.
- The result list will always be sorted from the maximum number of hits on down.
- Each word occurrence counts as a hit, even if its on the same page.
- Results are merged so that two words with two hits each on the same page will show up as 4 hits for the same word.
The code can be divided into four main sections, which are outlined in Table 1.
| Component | Description |
| HTML Tokenizer | Tokenizes an HTML file into individual elements. A token is either a word, a (double-quoted) string or a (punctuation) symbol. |
| HTML Parser | A parser which recognizes HTML tags, attributes and text content. The parser allows a calling program to walk through the elements in the order they are encountered. |
| Index Elements | Our index collects a word list with associated sets of title, filename and hit count for each page. The index is able to write itself out to a file and can be read back in pieces as may be useful at runtime. |
| Search Engine | The search engine traverses the index to find matches for each word and handles the boolean operations on the set, producing an output list of sorted word hits. It runs in a servlet which expects a POST operation with the search string as the only argument. |
The code in this article is designed to be loosely coupled and as reusable as possible.
The Tokenizer
The tokenizer is implemented with three classes, as shown in Figure 1. The tokenizer’s job is to break an HTML file into useful components for later parsing. The elements we’re interested are nicely constrained. We need to make a distinction between HTML tag information and the actual content of the file, so we’ll need to detect reserved meta-characters (like the angle brackets and equal signs), along with quoted string attributes to parse HTML tags. Anything which is not a tag is, effectively, the content we’re interested in.

Figure 1: Tokenizer Classes.
Listing 1 shows the HTMLToken class. We define three types of tokens, STRING, WORD and SYMBOL. Two constructors are supported. Though we always store the actual token text as a string internally, its convenient to expose a character argument for handling symbols. We also have a couple of accessors for getting the type and token values, along with a toString implementation that allows us to build a suitable string representation.
The HTMLTokenList class is trivial and won’t be listed, though you can find it online at www.java-pro.com. It extends ArrayList, which part of the Collections API (basically, a more efficient, unsynchronized Vector implementation). The HTMLTokenList class adds a getToken method which casts the HTMLToken returned by the get method for convenience.
If you take a look at the HTMLTokenizer class in Listing 2, you’ll see that we’re extending the Java StreamTokenizer. Since StreamTokenizer already handles quoted strings, we can dispense with a lot of the issues we might otherwise have to deal with. The trick is in setting up the options correctly. Our tokenizer ignores end-of-line characters, considers non-printable characters (0 to 32) to be white space. It defines the double quote as a string delimiter and marks all but the quote and non-printable characters as valid content, except for the four symbol characters (equal, forward slash and angle brackets), which are identified as ordinary characters.
HTMLTokenizer provides an extension to the nextToken method called nextHTMLToken, which returns an HTMLToken instance. The nextHTMLToken method determines the proper type of token from the StreamTokenizer’s ttype and sval instance variables, returning a more useful object that we an use later in our parser. We also provide a getTokenList method that tokenizes the whole stream and returns an HTMLTokenList. Since our parser needs to be able to look ahead, we can’t really call nextHTMLToken on-the-fly, so our implementation will always be using the getTokenList method.
Lets take a look at what it takes to parse HTML with our HTMLTokenList in hand.
HTML Parser
Our actual objective is to parse HTML files enough to separate the tags from the actual text content. If we didn’t do this, our search engine would pick up all the tags, tag attributes and meta-data and make the searches less useful. Many of the freebie solutions out there don’ take this into account, but we want something that reflects good quality on our site. To isolate the text from structural information, the HTMLParser will take the HTMLTokenList and produce a list of HTMLContent objects that reflect the primary types of information in the file. Figure 2 show the classes we’ll need to make this happen.
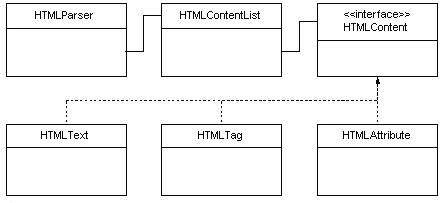
Figure 2: Parser Classes.
Its important to note that our intention is not to build a Document Object Model (DOM) of the HTML file, so if you’re expecting the same functionality as an XML parser, this is not what you’ll get. For this application, its more efficient to keep things linear, so the output of our parser will be a flat list of HTMLContent objects which we can walk through to pull out the content for indexing.
The HTMLContent interface is not listed because it has no actual methods (much like the Java Serializable interface). It is used to allow the HTMLText, HTMLTag and HTMLAttribute objects to be collected interchangeably. An abstract class extended by the same children would have accomplished the same basic goal. The real interface is provided by static parse methods which are implemented by each of the HTMLContent instances, but neither interfaces nor abstract classes allow you to declare static methods.
Listing 3 shows the HTMLParser class. Our constructor expects an HTMLTokenList and uses a nextItem method to parse each element on a per call basis. Each of the elements provide a static parse method to do the actual parsing, delegating the work to the objects that understand their own criteria. A tag is always recognizable by the open angle bracket symbol and may contain optional attributes or be a closing tag. If an element is not a tag, it is effectively text content.
Like the HTMLTokenizer class, HTMLParser provides a convenience method that returns a complete list of elements. The getContentList method returns an HTMLContentList instance, which is not listed for the same reasons HTMLTokenList was left out. It extends ArrayList and merely adds a getContent method to retrieve elements without having to cast them explicitly.
Listing 4 shows the HTMLTag class, which stores a name, end tag flag and an optional HTMLAttributeList. Aside from a number of accessor and a toString method, the real heart of the class is the static parse method. Because the HTMLTokenList is accessible to us, we can look ahead and perform operations on the list, removing parsed items as we confirm them. If the first token is an opening angle bracket, we continue. Otherwise, we return null, indicating that this is not a tag. If it is a tag, it might be an end tag with a forward slash, in which case we expect no attributes, set the end flag, get the name an pop the three tokens from the list. Notice that this is always done in reverse order to preserve the sequence. It this is not an ending tag, we just grab the name and pop the opening bracket and the tag name off the token list.
After all this, we check for attributes using a similar mechanism, delegated to the HTMLAttribute class. HTMLAttribute’s static parse method looks for name-equal-value sequences, returning null when there is no match, or popping the values off the token list when a match is found and returning an HTMLAttribute object. After checking for attributes the HTMLTag parse method looks for closing angle brackets and returns the HTMLTag object that was parsed.
The more astute reader may be wondering what happens if the HTMLTag parsing fails, returning null, after popping the opening tag. A more robust parser should restore these values before returning, but HTML does not allow angle brackets inside the text, so this implies that there was a syntax error in the page. I’ve made no attempt to correct for these possibilities in the code. I leave that as an exercise for you if you think its important. For this application, the indexer should only be run on well-formed HTML pages so this should never be an issue.
We’ll skip the HTMLAttribute and HTMLText listings but mention them here briefly. You can get them online at www.java-pro.com. HTMLAttribute saves a name and value string and provides accessors to reach them. Aside from the toString method, the static parse method does all the work and functions like a simpler version of the HTMLTag parse method.
The HTMLText static parse method walks through the token list and builds a string that concatenates all the elements together with inserted spaces until it sees an opening tag delimiter (an angle bracket). There’s also an HTMLAttributeList class, which is just like the other list implementations, extending ArrayList, with a couple of convenience accessors for retrieving attributes by name or index.
The Index
Our search engine solution relies on a one-time indexing process which is run on the web server whenever HTML content is changed. It’s up to the WebMaster to perform this task whenever content changes. To support fast searches, we will use a mapping between words and their occurrences in given documents. The information hierarchy is organized by individual words for quick lookup and may include several links for any given word. Figure 3 shows the classes involved and Figure 4 shows the structure we use to organize this into a Index which contains an IndexLinkSet for each word, each of them containing one of more IndexLink instances.

Figure 3: The Index Classes.
One of our design assumptions is that the web site being indexed is fairly small. To keep our index organized, our Index class extends the Collections HashMap class. The IndexLinkSet class extends TreeSet, which also keeps the elements sorted. In the case of a IndexLinkSet, however, we need to sort primarily by the number of hits to be effective, which means the IndexLink elements must implement the Sortable interface. Our job is slightly complicated by other uses this interface gets put to. The contains method in the Set interface, for example, uses it to determine whether an object is already contained by the Set.

Figure 4: Index Structure.
Listing 5 shows code for the IndexLink class. The primary purposes of this element is to store the title, file link and number of hits for a given word. The word itself is stored elsewhere but this class reports the number of occurrences of that word in a given file. The toString method returns a string with this information for debugging. The toHTML method returns a string in HTML format, as a row in a table with a link in the first column and the number of hits in the right. We also provide various accessors, including a couple of convenient incrementHits methods, and a parseLink method that takes formatted output from our index file and reads it back into a IndexLink instance.
The key method in this class is the compareTo method, which has to handle proper sorting. Things are complicated by the fact that we need to also compare entries in the Set and the contains method relies on the compareTo method rather than equals, as suggested in the documentation. Our equals method returns true if the titles between two IndexLink objects are the same. The compareTo method only indicates equality if the titles are equal and the hit count is the same.
The IndexLinkSet class extends TreeSet and stores the word associated with the set in an instance variable, exposing a few accessor methods for retrieving and setting a word. There’s nothing overly tricky in this class, so we’ll post it online rather than listing it here. The toString method returns a formatted string with the word, an equal sign and a comma-delimited set of IndexLink strings. This is how we store the data in our index file. The parseLinkSet method reverses this process and reconstructs a IndexLinkSet from an equivalent string.
If a IndexLink element already exists in our Set, the addLink method increments the value using the incrementHits method in IndexLink. Otherwise, the new link is added to the set. We implement union and intersection methods, which are used to merge two IndexLinkSet instances together, based on the kind of search that was performed. Our objective is to eliminate duplication and to correlate hits on the same word in the same file as a cumulative hit value. Whether we use union or intersection depends on whether our search was a boolean OR or AND search, respectively.
Listing 6 shows the Index class, which extends the Java Collections’ HashMap. It implements four methods. The first, addString, takes an HTMLContent string and title/filename arguments and creates a mapping between each word and the respective file, counting hits along the way. The isHTMLPunctuation method is merely a utility method to avoid inserting HTML punctuation tokens. The addLink method adds new word entries and extends existing ones when hits are added by first checking for existing IndexLinkSet entries. Finally, the writeFile method stream the Index content to a file, which is effectively our index file.
Application
The Indexer class in Listing 7 is a command line utility which traverses the directories from a given root path. The paths the program walks through use the native File.separator to avoid any platform dependencies, so the command line should be a natively appropriate path on the web server. Notice that the URLs are all relative to this root, so the actual path must be the root of the web server content you want to make searchable. The file name placed in the IndexLink object is made URL-specific by using the forward slash (‘/’) character. The title for an IndexLink is the file name without any path information. You can easily make this the actual html title, but in my experience these are often missing, so I prefer using the file name. This is easy enough to change if you want to make it slightly more user-friendly. Just be sure you site sets a suitable title for each of the html files you create.
The search engine itself, in Listing 8, is very simple. We provide a matchWord method which returns a IndexLinkSet from the index file. The search is linear but the test is very fast and we use a BufferedReader to speed things up. The mechanism looks at each line and check to see if it begins with our search word. If it does, we parse the remaining information and return a IndexLinkSet. To handle boolean searches, we add a more generic search method, which tokenizes the search string and seeks the individual words by calling the matchWord method. After each pair of words, we merge the results using either the union or intersection operators in the IndexLinkSet objects. If the search string has no conjunctions, we assume this is a disjunctive (OR) search, otherwise, we parse out the conjunctions and handle the operation accordingly.
Our final class is the SearchServlet, which merely wraps the Search class with an appropriate interface to handles a POST request, with a string argument named search. The result is returned on the output stream.
Deployment
To run the Indexer, all you have to do is provide the web site root path (using a fully specified native path) as the only argument on the command line. Having run the Indexer, put the search.index file in the root of your web site so the SearchServlet can find it. Put the class files from this article in the servlets directory on your web server and make sure the Java 1.1 Collection API classes are available to your servlet engine. If you’re using Java 1.2, the classes are already there. You need to add the servlet index argument to your servlet.properties file. Your entries should look something like this:
servlet.SearchServlet.args=index=f:\\website\\search.index
servlet.SearchServlet.code=SearchServlet
Finally, put the SearchEngine.html file on your web site and load it from a browser. You should be able to make queries on your system and see the results popup in a new window. Figures 4 and 5 show what the search and results pages should look like.
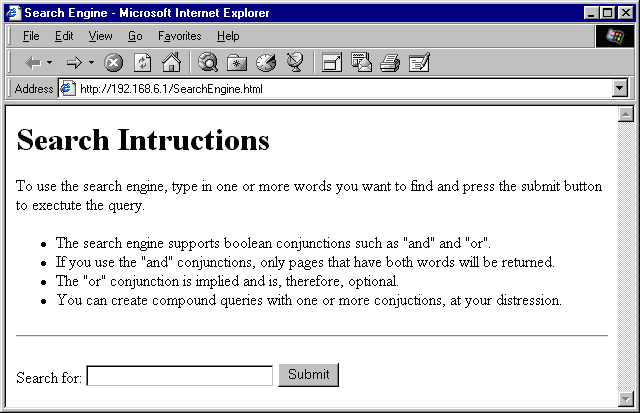
Figure 4: The Search Page. This page can be customized as you like. To make the results appear in another window, you can use the FORM tag's TARGET attribute. The instructions can be improved or removed, as you see fit.
Figure 5 shows what a typical result page might look like.
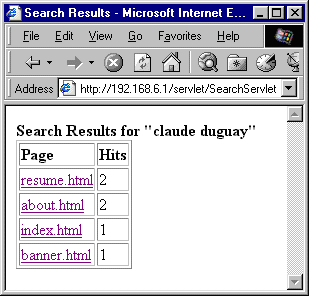
Figure 5: Search Results. The result list is sorted by the number of hits found in each page. For the string "claude duguay", the conjunction is assumed to be OR, so the two hits on the first two results indicate that either claude or duguay were found twice or both were found once each.
Summary
This article presented a solution that provides site searching facilities for a small web site. The result is not designed for scaleability but demonstrates some interesting techniques for tokenizing, parsing and indexing documents which can certainlybe applied to larger systems. There are, of course, commercial products that go well beyond this approach, but sometimes keeping things simple is all you really need. The classes in this project are generally reusable and relatively well delineated. I hope you’ll find them useful and the information in this article enlightening in some way.
Listing 1
public class HTMLToken
{
public static final int WORD = 1;
public static final int STRING = 2;
public static final int SYMBOL = 3;
protected int type;
protected String token;
public HTMLToken(int type, char token)
{
this(type, "" + token);
}
public HTMLToken(int type, String token)
{
this.type = type;
this.token = token;
}
public int getType()
{
return type;
}
public String getToken()
{
return token;
}
public String toString()
{
switch(type)
{
case WORD: return "word(" + '"' + token + '"' + ")";
case STRING: return "string(" + '"' + token + '"' + ")";
default: return "symbol('" + token + "')";
}
}
}
Listing 2
import java.io.*;
public class HTMLTokenizer extends StreamTokenizer
{
public HTMLTokenizer(Reader reader)
{
super(reader);
resetSyntax();
eolIsSignificant(false);
whitespaceChars('\u0000', '\u0020');
quoteChar('"');
wordChars('\u0021', '"' - 1);
wordChars('"' + 1, '\uFFFF');
ordinaryChar('<');
ordinaryChar('>');
ordinaryChar('=');
ordinaryChar('/');
}
public HTMLToken nextHTMLToken() throws IOException
{
int type = nextToken();
if (type == TT_EOF) return null;
switch(type)
{
case TT_WORD:
return new HTMLToken(HTMLToken.WORD, sval);
case '"':
return new HTMLToken(HTMLToken.STRING, sval);
default:
return new HTMLToken(HTMLToken.SYMBOL, (char)ttype);
}
}
public HTMLTokenList getTokenList()
throws IOException
{
HTMLTokenList list = new HTMLTokenList();
while (true)
{
HTMLToken token = nextHTMLToken();
if (token == null) break;
else list.add(token);
}
return list;
}
}
Listing 3
import java.util.*;
import java.io.*;
public class HTMLParser
{
protected HTMLTokenList tokens;
public HTMLParser(HTMLTokenList tokens)
{
this.tokens = tokens;
}
public HTMLContent nextItem()
{
HTMLContent content = HTMLTag.parse(tokens);
if (content == null) content = HTMLText.parse(tokens);
return content;
}
public HTMLContentList getContentList()
throws IOException
{
HTMLContentList list = new HTMLContentList();
while (true)
{
HTMLContent content = nextItem();
if (content == null) break;
list.add(content);
}
return list;
}
}
Listing 4
import java.util.*;
public class HTMLTag implements HTMLContent
{
protected String name;
protected boolean end;
protected HTMLAttributeList attributes;
public HTMLTag(String name, boolean end)
{
this(name, end, new HTMLAttributeList());
}
public HTMLTag(String name, boolean end, HTMLAttributeList attributes)
{
this.name = name;
this.end = end;
this.attributes = attributes;
}
public boolean hasName(String name)
{
return this.name.equalsIgnoreCase(name);
}
public String getName()
{
return name;
}
public void setName(String name)
{
this.name = name;
}
public boolean isEnd()
{
return end;
}
public HTMLAttributeList getAttributes()
{
return attributes;
}
public static HTMLTag parse(HTMLTokenList tokens)
{
String name;
if (tokens.size() <= 0) return null;
boolean end = false;
if (tokens.tokenAt(0).getToken().equals("<"))
{
if (tokens.tokenAt(1).getToken().equals("/"))
{
end = true;
name = tokens.tokenAt(2).getToken();
tokens.remove(2);
tokens.remove(1);
tokens.remove(0);
}
else
{
name = tokens.tokenAt(1).getToken();
tokens.remove(1);
tokens.remove(0);
}
}
else return null;
HTMLAttributeList attributeList = new HTMLAttributeList();
while (true)
{
HTMLAttribute attribute = HTMLAttribute.parse(tokens);
if (attribute == null) break;
attributeList.add(attribute);
}
if (!tokens.tokenAt(0).getToken().equals(">")) return null;
tokens.remove(0);
return new HTMLTag(name, end, attributeList);
}
public String toString()
{
StringBuffer buffer =
new StringBuffer("<" + (end ? "/" : "") + name);
for (int i = 0; i < attributes.size(); i++)
{
buffer.append(" " + attributes.get(i).toString());
}
return new String(buffer + ">");
}
}
Listing 5
import java.util.*;
public class IndexLink implements Comparable
{
public static final int COMPARE_HITS = 1;
public static final int COMPARE_NAME = 2;
protected int compareType = COMPARE_NAME;
protected String title;
protected String link;
protected int hits;
public IndexLink(String title, String link)
{
this.title = title;
this.link = link;
hits = 1;
}
public boolean equals(Object obj)
{
if (obj instanceof IndexLink)
{
IndexLink other = (IndexLink)obj;
return title.equals(other.title);
}
return false;
}
public int compareTo(Object obj)
{
if (obj instanceof IndexLink)
{
IndexLink other = (IndexLink)obj;
if (hits < other.hits) return 1;
if (hits > other.hits) return -1;
if (equals(obj)) return 0;
}
return -1;
}
public void incrementHits()
{
incrementHits(1);
}
public void incrementHits(int count)
{
hits += count;
}
public String getTitle()
{
return title;
}
public String getLink()
{
return link;
}
public int getHits()
{
return hits;
}
public void setHits(int hits)
{
this.hits = hits;
}
public String toString()
{
return hits + "|" + title + "|" + link;
}
public String toHTML()
{
return "<TR><TD><A HREF=" + '"' + link + '"' + ">" +
title + "</A></TD><TD>" + hits + "</TD></TR>";
}
public static IndexLink parseLink(String text)
{
StringTokenizer tokenizer = new StringTokenizer(text, "|", false);
int hits = Integer.parseInt(tokenizer.nextToken());
String title = tokenizer.nextToken();
String link = tokenizer.nextToken();
IndexLink indexLink = new IndexLink(title, link);
indexLink.setHits(hits);
return indexLink;
}
}
Listing 6
<PRE>import java.io.*;
import java.util.*;
public class Index extends HashMap
{
public int count = 0;
public int total = 0;
public void addString(String text, String title, String filename)
{
StringTokenizer tokenizer = new StringTokenizer(text,
" \t\n\r!@#$%^&*()-_+=[]{};:'.,/?\\|~`\"", false);
while(tokenizer.hasMoreTokens())
{
String word = tokenizer.nextToken();
if (word.length() > 1 &&
!isHTMLPunctuation(word))
{
System.out.print(".");
addLink(word, title, filename);
}
}
}
public boolean isHTMLPunctuation(String word)
{
return
word.equalsIgnoreCase("quot") ||
word.equalsIgnoreCase("amp") ||
word.equalsIgnoreCase("gt") ||
word.equalsIgnoreCase("lt") ||
word.equalsIgnoreCase("eq");
}
public void addLink(String word, String title, String file)
{
total++;
IndexLinkSet set;
IndexLink link = new IndexLink(title, file);
if (containsKey(word))
{
set = (IndexLinkSet)get(word);
}
else
{
set = new IndexLinkSet(word);
put(word, set);
count++;
}
set.addLink(link);
}
public void writeFile(String filename)
throws IOException
{
PrintWriter writer = new PrintWriter(new FileWriter(filename));
Iterator iterator = keySet().iterator();
while (iterator.hasNext())
{
String key = (String)iterator.next();
writer.print(key + "=");
writer.println(get(key).toString());
writer.flush();
}
writer.close();
}
}
Listing 7
import java.io.*;
import java.util.*;
public class Indexer
{
public Index index = new Index();
public int files = 0;
public void traverse(File root)
{
traverse(root, root);
}
public void traverse(File root, File path)
{
String[] list = path.list();
for (int i = 0; i < list.length; i++)
{
File entry = new File(path, list[i]);
String file = entry.getName();
if (entry.isDirectory())
{
//System.out.println("Directory: " + file);
traverse(root, entry);
}
else
{
//System.out.println("File: " + file);
if (file.toLowerCase().endsWith(".html") ||
file.toLowerCase().endsWith(".htm"))
{
processFile(index, entry.getAbsolutePath(), file);
}
}
}
}
public String[] parsePath(String pathString, String delim)
{
StringTokenizer tokenizer = new StringTokenizer(pathString, delim, false);
int count = tokenizer.countTokens();
String[] pathArray = new String[count];
int index = 0;
while (tokenizer.hasMoreTokens())
{
pathArray[index] = tokenizer.nextToken();
index++;
}
return pathArray;
}
public String buildPath(String[] pathArray, String delim)
{
StringBuffer buffer = new StringBuffer();
for (int i = 0; i < pathArray.length; i++)
{
if (i > 0) buffer.append(delim);
buffer.append(pathArray[i]);
}
return buffer.toString();
}
public void processFile(Index index, String filename, String url)
{
try
{
files++;
System.out.println("Processing: " + filename);
FileReader fileReader = new FileReader(filename);
BufferedReader bufferedReader = new BufferedReader(fileReader);
HTMLTokenizer tokenizer = new HTMLTokenizer(bufferedReader);
System.out.println("Tokenizing...");
HTMLTokenList tokens = tokenizer.getTokenList();
fileReader.close();
System.out.println("Parsing...");
HTMLParser parser = new HTMLParser(tokens);
System.out.println("Indexing");
while(true)
{
HTMLContent content = parser.nextItem();
if (content == null) break;
if (content instanceof HTMLText)
{
url = buildPath(parsePath(url, File.separator), "/");
String[] path = parsePath(filename, File.separator);
String title = path[path.length - 1];
index.addString(content.toString().toLowerCase(),
title, "/" + url);
}
}
System.out.println();
}
catch (IOException e)
{
e.printStackTrace();
}
}
public static void main(String[] args)
throws IOException
{
if (args.length != 1)
{
System.out.println("Usage: java Indexer <WebSiteRootDirectory>");
System.exit(0);
}
Indexer indexer = new Indexer();
indexer.traverse(new File(args[0]));
System.out.println("Total files: " + indexer.files);
System.out.println("Total words: " + indexer.index.total);
System.out.println("Unique words: " + indexer.index.count);
indexer.index.writeFile("search.index");
}
}
Listing 8
import java.io.*;
import java.util.*;
public class Search
{
protected String indexFile;
public Search(String indexFile)
{
this.indexFile = indexFile;
}
public IndexLinkSet matchWord(String word)
throws IOException
{
String found = null;
String match = word.toLowerCase() + "=";
BufferedReader reader = new BufferedReader(
new FileReader(indexFile));
while (true)
{
String line = reader.readLine();
if (line == null) break;
if (line.startsWith(match))
{
found = line.substring(match.length());
break;
}
}
reader.close();
if (found == null) return null;
return IndexLinkSet.parseLinkSet(word, found);
}
public IndexLinkSet matchHits(String text)
throws IOException
{
StringTokenizer tokenizer = new StringTokenizer(text, " ", false);
if (!tokenizer.hasMoreTokens()) return null;
IndexLinkSet hits = matchWord(tokenizer.nextToken());
boolean intersection = false;
while (tokenizer.hasMoreTokens())
{
String token = tokenizer.nextToken();
if (token.equalsIgnoreCase("and") &&
tokenizer.hasMoreTokens())
{
token = tokenizer.nextToken();
intersection= true;
}
if (token.equalsIgnoreCase("or") &&
tokenizer.hasMoreTokens())
{
token = tokenizer.nextToken();
intersection = false;
}
IndexLinkSet more = matchWord(token);
if (hits != null) hits = intersection ?
hits.intersection(more) : hits.union(more);
else hits = more;
}
return hits;
}
public String search(String text)
throws IOException
{
StringBuffer buffer = new StringBuffer();
IndexLinkSet hits = matchHits(text);
if (hits != null)
{
buffer.append("<HTML><HEAD><TITLE>Search Results</TITLE></HEAD><BODY>");
buffer.append("<B>Search Results for ");
buffer.append('"' + text + '"' + "</B>");
buffer.append(hits.toHTML());
buffer.append("</BODY></HTML>");
}
else buffer.append("<P>No pages found!");
return buffer.toString();
}
public static void main(String[] args)
throws IOException
{
Search searcher = new Search("search.index");
System.out.println(searcher.search(args[0]));
}
}