
ORIGINAL DRAFT
Numerous applications require parsing data in one form or another. Sadly, the StringTokenizer and StreamTokenizer classes, provided as part of the standard Java distribution, fall short of what’s required in most cases. Building your own tokenizer each time you need to parse something is both time-consuming and usually unnecessary. This article centers on the creation of a flexible, extensible tokenizer that you can reuse whenever you need to write a parser.
The FlexTokenizer uses a plugable Tokenizer/Token paradigm. A Token represents the element that was tokenized, which could be a number, string, symbol or other token. A Tokenizer is the engine that recognizes a Token in the sequence of text presented to it. A Tokenizer is responsible for recognizing and creating a given token. The FlexTokenizer allows you to add and remove Tokens and Tokenizers as you see fit.
FlexTokenizer also lets you define the sequence in which tokens will be considered. For example, a ‘/’ character may be the start of a comment or a symbol, so the comment should be considered first. If the associated Tokenizer fails, then we assume it was a symbol. The comment example is especially relevant. In our default implementation, we can tokenize both kinds of Java comments, so there are actually three kinds of Tokens that could begin with the ‘/’ character, the two comment types and a symbol token. Each needs to be considered in proper sequence.
I can’t write this article without giving proper credit to Steve John Metsker, who recently published a book called "Building Parsers with Java". The ideas presented in the book are incredibly valuable and you should definitely buy this book if you’re serious about building parsers in Java. The FlexTokenizer is inspired by the book but extends the fundamental ideas in several ways.
The notion of using sequences is entirely mine, as is the inclusion of positional information with each token. In my experience, this information is indispensable when trying to debug a parser or for providing useful feedback to the user. We also makes heavy use of a BufferedReader for look-aheads rather than a PushbackInputStream, which can only deal with one character at a time and deals with text at the byte level rather than the character level.
et’s take a look at the classes required to make this work. Figure 1 shows the relationships between each of the classes involved. There are two major interfaces, Token and Tokenizer. Each includes default implementations as inner classes. Both of these interfaces include an Abstract implementation and the Tokenizer includes two additional abstract classes that pull together commonalties for a few of the concrete classes.
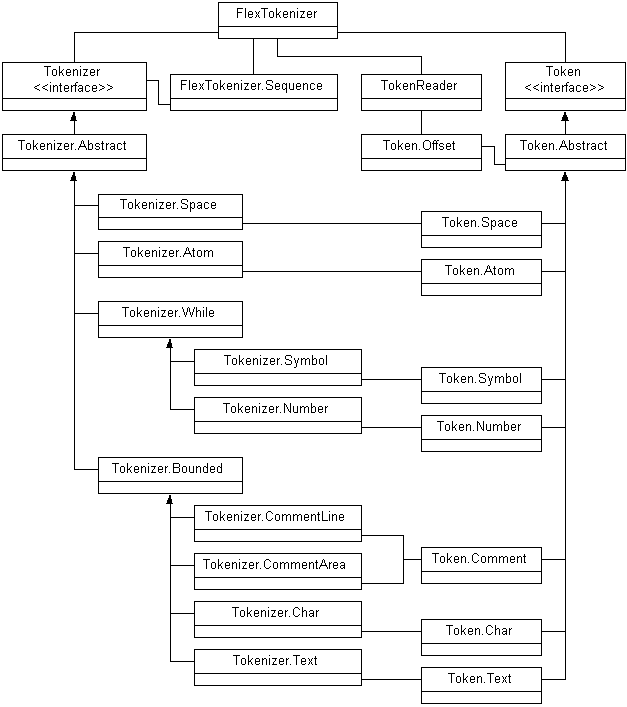
Figure 1: FlexTokenizer classes.
The FlexTokenizer uses Sequence objects to collect Tokenizers and associate them with initial characters. You’ll see how this works when we take a closer look at the code. The TokenReader uses the Offset class to collect position information. You’ll see that each class maximizes flexibility and offers options you can capitalize on when you have more specific needs. As it stands, this tokenizer will easily deal with Java source code. The main method in FlexTokenizer demonstrates this capability.
Naturally, we don’t have room to look at each of the classes in this project. You can find them all online at www.java-pro.com. We’ll take a look at the more important classes, including TokenReader and FlexTokenizer itself, as well as an illustrative Tokenizer and associated Token. Let’s take a quick look at the two interfaces we’ll be using.
public interface Token
{
public Object getToken();
public void setToken(Object token);
public Offset getOffset();
public void setOffset(Offset pos);
public boolean isIgnorable();
public void setIgnorable(boolean ignorable);
}
The Token interface provides access to the three elements included in each of our tokens. We need access to the token itself, which may be any object, such as a Character, Number or String. We need access to the Offset object, which encapsulates position information, including an offset from the beginning of the stream, as well as the line number and line offset for the token.
The ignorable flag is used to skip over certain tokens when processing a given stream. Comments and white space, for example, can be returned or ignored by using this mechanism. Tokens that are ignorable are flagged in advance so that the FlexTokenizer can recognize ignorable tokens as it operates.
public interface Tokenizer
{
public Token nextToken(TokenReader reader)
throws IOException;
}
The Tokenizer interface is simple. It takes a TokenReader reference and returns a Token object, if one can be constructed at the current position. If the Token could not be constructed, the Tokenizer returns a null value. The FlexTokenizer can then reset the stream position and try processing another Tokenizer in the Sequence, if one is available.
Before we look at the Token and Tokenizer implementation, lets take a quick look at the code for TokenReader in Listing 1. TokenReader extends BufferedReader and takes advantage of the mark method supported by the reader. We override the read, mark and reset methods to capture position information. Since the FlexTokenizer always reads one character at a time, we can ignore the other read methods supported by the Reader interface.
All we need to do is increment our position counters every time the read method is called. When we mark a position, the current position is kept in a set of instance variables who’s names are prefixed by the word mark. When the reset method is called, we reset the current position from these values. Notice that the superclass methods are called in each of these cases, so the fundamental behavior is identical to a BufferedReader.
The only other method in TokenReader is getOffset, which constructs an Offset object from the file offset, line number and line offset. This is used by each of the Tokenizer implementations to add offset information to the Token being constructed. We’ll skip over the Offset implementation but mention that it does little more than provide accessors for the three position integers and a toString method to make it easy to print results.
Since the Symbol tokenizer is the one you are most likely to want direct access to, we’ll take a quick look at the implementation. The Token.Symbol class extends Token.Abstract and exposes a constructor and a toString method. Token.Abstract exposes the Token interface and adds a toString method that expects two String arguments which identify the name of the token and a string representation for the value. This makes it easier for subclasses to implement their own toString methods.
The Tokenizer.Symbol class extends Tokenizer.While, which extends Tokenizer.Abstract. The Abstract class implements three utility methods that can be used by subclasses, peek, startsWith and endsWith. The peek method uses the TokenReader mark to mark the current position, reads a character and resets the current position. The startsWith and endsWith methods operate on StringBuffer objects, using the substring method to minimize String object creation.
The Tokenizer.While class aggregates behavior common to tokenizers that need to append characters to their stack until a mismatch is found. This is true of numbers and symbols in our implementation. Having an abstract class like Tokenizer.While helps eliminate duplication and makes it easier to create new tokenizers with the same fundamental behavior.
Tokenizer.While implements the nextToken method required by the Tokenizer interface and uses two abstract methods. The first, isValid, is used to validate the token buffer as we go along. When this method returns false, we have stepped past the last character in the token. The createToken method is used when we’ve decided that a valid token is available. Both these method implementations are specific to a given Tokenizer subclass, though the commonality is captured by the nextToken method.
Listing 2 shows the code for Tokenizer.Symbol, which extends the Tokenizer.While abstract class. As such, we implement the isValid and createToken methods. The latter is simple in that all it does is create an instance of a Token.Symbol with suitable arguments. The isValid method always returns true for a single character and looks at an internal list to determine whether the token is currently valid.
To support multi-character symbols, we use an extendedSymbolList instance of ArrayList, which holds a list of strings that are kept in length order. The add method intentionally keeps longer strings near the beginning of the list so that the isValid method does not report failure on a shorter token prematurely. Along with the add method, we also support a remove and a clear method to manage to symbol token list.
You’ll notice that the Tokenizer.Symbol constructor sets up a series of symbols that are applicable to parsing Java. These can easily be cleared, by calling the clear method, and new symbols can be added. This is an operation you’ll find fairly common when dealing with different parsers and languages. Let’s take a look at the FlexTokenizer implementation to see how you can use Tokenizers to accomplish different goals.
Listing 3 shows the code for FlexTokenizer. Because there are inner classes in both Listing 2 and 3, I’ve left comments indicating some removal. The missing inner class in the FlexTokenizer listing is for Sequence, which extends ArrayList and provides a few utility constructors to help create single, dual and triad collections of Tokenizers. The only implemented method is getTokenizer, which casts the lookup of a given indexed value to a Tokenizer object for convenience.
The code for FlexTokenizer relies on a character table that associates Tokenizers with characters. This mechanism allows the FlexTokenizer to use the correct Tokenizer when it encounters a given initial character. For example, a double quote character is associated with the Tokenizer.Text object. These associations are indirect in that Tokenizer objects are made part of a Sequence collection, which is then associated with a character in the charTable array.
The Sequence paradigm allows us to associate multiple Tokenizer objects with a given character in the charTable. That means that, should one tokenizer fail, with the nextToken method returning a null value, the next Tokenizer in the Sequence can be tried. The order in which tokenizers are applied is, therefore, completely under your control.
As you look through the code, you’ll see instance variables for skipIgnorables, which allows us to skip ignorable tokens in the output; readAheadLimit, which sets the maximum number of characters we can look ahead before resetting a mark in the TokenReader; the charTable, which holds character/Sequence associations; and a reference to a TokenReader.
What follows is a set of declarations for Tokenizer and Sequence instances that are used by default. We do this to avoid duplication and to provide a convenient way for you to associate combination of your choosing. The initCharTable method does the actual default association work. You can, therefore, either call the setTokenizerSequence method directly to associate a Sequence with a range of characters or you can override the initCharTable method in a subclass.
The two constructors we provide allow you to pass in a text string or a TokenReader. We provide accessors for the skipIgnorable option and a utility method called peek for looking ahead one character at a time. The real work is accomplished in the nextToken method, which you can call repeatedly until you get a null Token.
After peeking at the first available character, we can find the associated Sequence in the charTable. With a Sequence in hand, we step through each Tokenizer and call it’s nextToken method until we get a non-null response, which will always be the next matchable token. Before returning the token, we check whether it’s ignorable and recursively call nextToken if it is, in order to get the next available token.
I’ve left the main method in the FlexTokenizer class to demonstrate typical usage. Since we can count on having access to this source code, a FlexTokenizer instance is initialized to parse the "FlexTokenizer.java" file. All we have to do is wrap a TokenReader around a FileReader to do this. The rest of the code simply calls nextToken until we get a null value and prints each token as we go. You’ll see something suitably readable because each Token implements the toString method.
FlexTokenizer is a powerful tokenizer, moving well beyond the StringTokenizer and StreamTokenizer classes offered with standard Java releases. FlexTokenizer can be used to tokenize virtually any text source and new tokens can easily be created to handle any kind of special need. The ability to associate sequences of tokenizers with starting characters makes it easy to build tokenizers for a wide variety of applications.
I think you’ll find the FlexTokenizer architecture especially flexible and the position offset information indispensable when you develop your own parser solutions. Few existing tokenizer implementations deal effectively with escape characters in string or character literals. FFlexTokenizer easily handles these issues and makes the process of implementing tokenizers virtually transparent. All these features make FlexTokenizer ultimately reusable. I hope you’ll agree.
Listing 1
import java.io.*;
public class TokenReader
extends BufferedReader
{
protected int fileOffset = 0;
protected int lineNumber = 0;
protected int lineOffset = 0;
protected int markFileOffset = 0;
protected int markLineNumber = 0;
protected int markLineOffset = 0;
public TokenReader(Reader reader)
{
super(reader);
}
public int read() throws IOException
{
int chr = super.read();
fileOffset++;
lineOffset++;
if (chr == '\n')
{
lineNumber++;
lineOffset = 0;
}
return chr;
}
public void mark(int max) throws IOException
{
markFileOffset = fileOffset;
markLineNumber = lineNumber;
markLineOffset = lineOffset;
super.mark(max);
}
public void reset() throws IOException
{
fileOffset = markFileOffset;
lineNumber = markLineNumber;
lineOffset = markLineOffset;
super.reset();
}
public Token.Offset getOffset()
{
return new Token.Offset(
fileOffset, lineNumber, lineOffset);
}
}
Listing 2
public interface Tokenizer
{
// ... CODE REMOVED FOR LISTING ...
public static class Symbol extends While
{
protected ArrayList extendedSymbolList =
new ArrayList();
public Symbol()
{
add("==");
add("!=");
add(">=");
add("<=");
add("&&");
add("||");
add("--");
add("++");
add("-=");
add("+=");
add("*=");
add("/=");
}
public void add(String symbol)
{
boolean added = false;
int len = symbol.length();
int count = extendedSymbolList.size();
for (int i = 0; i < count; i++)
{
String test = (String)
extendedSymbolList.get(i);
if (len > test.length())
{
extendedSymbolList.add(i, symbol);
added = true;
}
}
if (!added) extendedSymbolList.add(symbol);
}
public void remove(String symbol)
{
extendedSymbolList.remove(symbol);
}
public void clear()
{
extendedSymbolList.clear();
}
public boolean isValid(String text)
{
if (text.length() == 1) return true;
int count = extendedSymbolList.size();
for (int i = 0; i < count; i++)
{
String symbol = (String)
extendedSymbolList.get(i);
if (symbol.startsWith(text)) return true;
}
return false;
}
public Token createToken(
Object token, Token.Offset offset)
{
return new Token.Symbol((String)token, offset);
}
}
// ... CODE REMOVED FOR LISTING ...
}
Listing 3
import java.io.*;
import java.util.*;
public class FlexTokenizer
{
// ... CODE REMOVED FOR LISTING ...
protected boolean skipIgnorables = true;
protected int readAheadLimit = 255;
protected TokenReader reader;
protected Sequence[] charTable = new Sequence[256];
public static final Tokenizer
SYMBOL_TOKENIZER = new Tokenizer.Symbol();
public static final Tokenizer
SPACE_TOKENIZER = new Tokenizer.Space();
public static final Tokenizer
TEXT_TOKENIZER = new Tokenizer.Text();
public static final Tokenizer
CHAR_TOKENIZER = new Tokenizer.Char();
public static final Tokenizer
NUMBER_TOKENIZER = new Tokenizer.Number();
public static final Tokenizer
ATOM_TOKENIZER = new Tokenizer.Atom();
public static final Tokenizer
COMMENT_LINE_TOKENIZER = new Tokenizer.CommentLine();
public static final Tokenizer
COMMENT_AREA_TOKENIZER = new Tokenizer.CommentArea();
public static final Sequence
SYMBOL_SEQUENCE = new Sequence(
SYMBOL_TOKENIZER);
public static final Sequence
SPACE_SEQUENCE = new Sequence(
SPACE_TOKENIZER,
SYMBOL_TOKENIZER);
public static final Sequence
TEXT_SEQUENCE = new Sequence(
TEXT_TOKENIZER,
SYMBOL_TOKENIZER);
public static final Sequence
CHAR_SEQUENCE = new Sequence(
CHAR_TOKENIZER,
SYMBOL_TOKENIZER);
public static final Sequence
NUMBER_SEQUENCE = new Sequence(
NUMBER_TOKENIZER,
SYMBOL_TOKENIZER);
public static final Sequence
ATOM_SEQUENCE = new Sequence(
ATOM_TOKENIZER,
SYMBOL_TOKENIZER);
public static final Sequence
COMMENT_SEQUENCE = new Sequence(
COMMENT_LINE_TOKENIZER,
COMMENT_AREA_TOKENIZER,
SYMBOL_TOKENIZER);
public FlexTokenizer(String text)
{
this(new TokenReader(new StringReader(text)));
}
public FlexTokenizer(TokenReader reader)
{
this.reader = reader;
initCharTable();
}
public void initCharTable()
{
setTokenizerSequence( 0, 255, SYMBOL_SEQUENCE);
setTokenizerSequence( 0, ' ', SPACE_SEQUENCE);
setTokenizerSequence( 'a', 'z', ATOM_SEQUENCE);
setTokenizerSequence( 'A', 'Z', ATOM_SEQUENCE);
setTokenizerSequence(0xc0, 0xff, ATOM_SEQUENCE);
setTokenizerSequence( '\'', '\'', CHAR_SEQUENCE);
setTokenizerSequence( '"', '"', TEXT_SEQUENCE);
setTokenizerSequence( '-', '-', NUMBER_SEQUENCE);
setTokenizerSequence( '.', '.', NUMBER_SEQUENCE);
setTokenizerSequence( '0', '9', NUMBER_SEQUENCE);
setTokenizerSequence( '/', '/', COMMENT_SEQUENCE);
}
public void setTokenizerSequence(
int from, int to, Sequence sequence)
{
for (int i = from; i <= to; i++)
{
charTable[i] = sequence;
}
}
public void setSkipIgnorables(boolean skipIgnorables)
{
this.skipIgnorables = skipIgnorables;
}
public boolean getSkipIgnorables()
{
return skipIgnorables;
}
protected int peek()
throws IOException
{
reader.mark(1);
int chr = reader.read();
reader.reset();
return chr;
}
public Token nextToken()
throws IOException
{
int chr = peek();
if (chr == -1) return null;
Token token = null;
Sequence sequence = charTable[chr];
reader.mark(readAheadLimit);
for (int i = 0; i < sequence.size(); i++)
{
reader.reset();
Tokenizer tokenizer = sequence.getTokenizer(i);
token = tokenizer.nextToken(reader);
if (token != null) break;
}
if (skipIgnorables && token.isIgnorable())
{
token = nextToken();
}
return token;
}
public static void main(String[] args)
throws IOException
{
String filename = "FlexTokenizer.java";
FlexTokenizer tokenizer = new FlexTokenizer(
new TokenReader(new FileReader(filename)));
Token tok;
while ((tok = tokenizer.nextToken()) != null)
{
System.out.println(tok);
}
}
}