
ORIGINAL DRAFT
One of the great things about Java is it’s built-in documentation engine. The JavaDoc engine is fully customizable, allowing developers to write their own processors, called Doclets. This month, we’re going to take advantage of XML’s powerful document structure to generate an intermediary representation from Java source code. This representation can easily be run through styles sheets or document processors to generate different types of output.
We’ll develop a set of flexible JavaDoc extension classes along the way. With these classes, we’ll implement a simple, plain-text output format and then a more sophisticated, semantically complete, XML representation. We won’t have enough room to illustrate the many things you can do with an XML representation for your Java documentation. I’ll leave that to your expanding imagination.
Let’s take a quick look at the Doclet infrastructure and the JavaDoc API. Implementing a Doclet is a simple matter of implementing a static method that looks like this:
public static boolean start(RootDoc root);
This method is expected to return true if things go well. From the RootDoc object, we can get an array of ClassDoc objects by calling the classes method. From there, we are free to process each class as we might see fit. There are numerous methods in the ClassDoc object that give us access to class-specific information, such as the class name and parent class, package and class imports, implemented interfaces, fields, constructors and methods. Each of these methods typically return objects that can be further decomposed.
JavaDoc documentation objects include ClassDoc, PackageDoc, FieldDoc, ConstructorDoc and MethodDoc, all of which inherit from a Doc class that provides a set of common methods. There’s no implied usage pattern in the Doclet interface, but developing Doclets leads quickly to some simple observations.
- Doclets typically process each class, in turn from the RootDoc list of classes.
- For each class, there is typically a list of packages, interfaces, fields, constructors and methods.
- For each documented class, you’ll typically have to organize these lists with useful delimiters.
Given that these requirements are pretty frequent, it would be nice to develop reusable interfaces and default implementations that do most of the work for us. The reason for using interfaces is primarily to maximize decoupling and to allow new implementations to be applied to the different layers of abstractions in the future.
Consistent with the three observations above, we’ll use three interfaces in our implementation. The first, ClassDocProcessor, implements a single method:
public interface ClassDocProcessor<BR>
{
public void processClass(ClassDoc classDoc);
}
The default implementation for ClassDocProcessor (called DefaultClassDocProcessor) will delegate list processing to an interface called ClassDocListProcessor. You can see the code for this interface in Listing 1. You’ll notice that the interface includes a start and end method that will tell implementers where they stand as each new class begins and ends its processing. The start method allows concrete implementations to handle class name and parent class information before continuing. The rest of the methods pass lists of various types for processing. By using this kind of interface, our processing becomes more event-driven and easier to implement.
A typical document output format requires these lists to be delimited in some way, either they are given section titles or begin/end tags are involved, in the case of XML or HTML, for example. Rather than force developers to implement loops with specialized handling for each of these list, it would be easier to have events that are item-based, rather than list-based. It’s important to support list-based handling so that default behaviors can be easily overridden, but the most common case will process each item independently, so a higher-level abstraction is warranted.
Listing 2 shows the ClassDocItemProcessor interface, which provides an item-based callback metaphor. Since list are still involved, each item typically has a start and end method associated with it so that pre- and post-processing can easily be done. To make this as easy as possible to use, our default implementation for the ClassDocProcessor will allow programmers to pass in either a ClassDocListProcessor or a ClassDocItemProcessor, depending on the abstraction layer you want to implement.
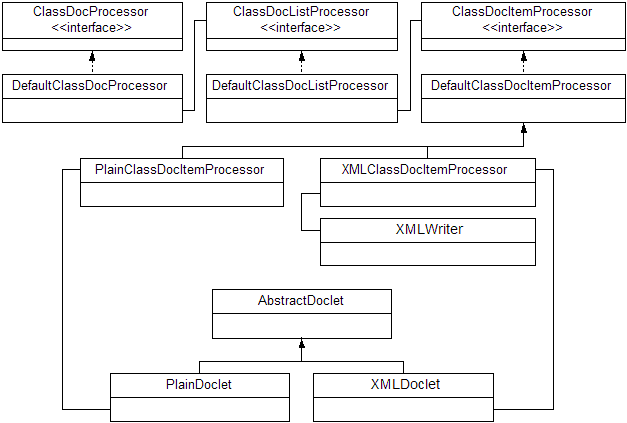
Figure 1: We provide three interface classes with associated default implementations to make it easy to work with Doclets, along with Plain and XML output implementations to demonstrate usage.
Figure 1 shows the classes in this project. As always, print space is limited, so you can download them from www.xmlmag.com. We’ve covered the major interfaces. For each interface there is a default implementation. The DefaultClassDocProcessor delegates work to the DefaultClassDocListProcessor, which in turn delegates work to the DefaultClassDocItemProcessor. The latter implements all the methods in the interface but does no actual work. It’s up to you to either develop your own implementation or to subclass DefaultClassDocItemProcessor and override those methods you want to handle.
The PlainClassDocItemProcessor and XMLClassDocItemProcessor classes do just that. We’ll use a utility XMLWriter class to handle the XML output. XMLWriter extends PrintWriter and provides a set of useful methods that support printing XML tags, attributes, content along with basic indentation support for readability.
The AbstractDoclet class implements a few variants for a static method that simplifies the use of our infrastructure. Each method, named processClassDocList, can be passed the ClassDoc list from the DocRoot along with either a ClassDocProcessor, ClassDocListProcessor or ClassDocItemProcessor, depending on the variant you use. Those variants that take a higher level abstraction get wrapped into the lower level default implementations for each respective interface.
It’s easy to see how you might implement a ClassDocItemProcessor that prints out information as it gets passed to each of the callback method. In fact, that’s exactly what the PlainClassDocItemProcessor class does, formatting each item type with a prefix or title to make it clear what you’re looking at. The PlainDoclet class extends AbstractDoclet and can easily be called with the following command line:
javadoc -doclet PlainDoclet *.java
Since most of the infrastructure work is handled by our default implementations, at various abstraction layers, implementing the ClassDocItemProcessor interface and a Doclet main class is all we need to do to handle a new format. Of course, if you want more control, all you need to do is implement the ClassDocListProcessor directly, or even the ClassDocProcessor if you don’t mind the extra work.
Lets take a look at the XMLClassDocItemProcessor in Listing 3, which actually generates XML output. This class makes heavy use of the XMLWriter class and is actually called by the XMLDoclet class. XMLDoclet, like the PlainDoclet class, inherits from the AbstractDoclet class and sets up the ClassDocItemProcessor in the start method. You can run it by calling:
javadoc -doclet XMLDoclet *.java
XMLClassDocItemProcessor uses a number of protected method to simplify the process. JavaDoc comments come in a few flavors, so we want to capture them within the definition for a given class-level, field, constructor or method definition. This method wraps content in a DOCS tag and delegates some of its work to the writeTag and writeParamTag methods. The first handles documentation tags, except for the parameter definitions, which have their own, specialized syntax.
The writeParameters method writes out parameters used in either a constructor or method. We write out the data type as an attribute and the actual parameter name as content between XML PARAMETER tags. These, like the DOCS information, get nested within the element being documented, so the PARAMETER information will be within the method or constructor tag it relates to.
The rest of the class handles each of the callback methods in the ClassDocItemProcessor interface. Because we know when each element list starts and ends, its easy to wrap the content in specific XML tags that describe what we’re dealing with, be it a set of fields, methods, constructors, etc.
You’ll notice that we flush the XMLWriter stream after each significant processing event to make sure the output doesn’t get too backed up. This isn’t, strictly necessary but it’s useful to see the processing as it happens when you’re writing to the console.
Most of the code is fairly straight forward, so I’ll recommend you take a closer look if anything seems non-obvious. The logic is fairly simple and the interface-based infrastructure makes it easy to implement different formats with relative ease. The major difference between the PlainClassDocItemProcessor and the XMLClassDocItemProcessor is that comments are handled by the XML variant and ignored by the Plain version. As well, the XML version nests lists of items within parent tags for easier downstream processing.
You’ve seen how easy it is to extend the Doclet model to generate alternate JavaDoc output and how you can apply this to producing an XML format that can be used as a source for other useful transformations. These transformations can be applied to publishing your documentation, storing key information in a database, sharing canonical representations, code analysis, and more. With the rights tools at hand, you’re bound only by your imagination.
Listing 1
import com.sun.javadoc.*;
public interface ClassDocListProcessor
{
public void processClassStart(ClassDoc doc);
public void processInterfaceList(ClassDoc[] list);
public void processPackageImportList(PackageDoc[] list);
public void processClassImportList(ClassDoc[] list);
public void processFieldList(FieldDoc[] list);
public void processConstructorList(ConstructorDoc[] list);
public void processMethodList(MethodDoc[] list);
public void processClassEnd();
}
Listing 2
import com.sun.javadoc.*;
public interface ClassDocItemProcessor
{
public void classStart(ClassDoc doc);
public void classEnd();
public void interfaceStart(int count);
public void interfaceDoc(ClassDoc doc);
public void interfaceEnd(int count);
public void packageImportStart(int count);
public void packageImportDoc(PackageDoc doc);
public void packageImportEnd(int count);
public void classImportStart(int count);
public void classImportDoc(ClassDoc doc);
public void classImportEnd(int count);
public void fieldStart(int count);
public void fieldDoc(FieldDoc doc);
public void fieldEnd(int count);
public void constructorStart(int count);
public void constructorDoc(ConstructorDoc doc);
public void constructorEnd(int count);
public void methodStart(int count);
public void methodDoc(MethodDoc doc);
public void methodEnd(int count);
}
Listing 3
import java.io.*;
import com.sun.javadoc.*;
public class XMLClassDocItemProcessor
extends DefaultClassDocItemProcessor
{
protected XMLWriter writer;
public XMLClassDocItemProcessor(PrintWriter writer)
{
this.writer = new XMLWriter(writer);
}
protected void writeComments(int depth, Doc doc)
{
Tag[] tags = doc.tags();
String comment = doc.commentText();
if (comment.equals("") && tags.length == 0) return;
writer.writeOpenTag(depth, "DOCS");
writer.println();
if (!comment.equals(""))
{
writer.writeSimpleTag(depth + 1, "COMMENT", comment);
writer.println();
}
for (int i = 0; i < tags.length; i++)
{
if (tags[i] instanceof ParamTag)
{
writeParamTag(depth + 1, (ParamTag)tags[i]);
}
else
{
writeTag(depth + 1, tags[i]);
}
}
writer.writeCloseTag(depth, "DOCS");
writer.println();
writer.flush();
}
protected void writeTag(int depth, Tag tag)
{
String name = tag.name();
if (name.startsWith("@"))
{
name = name.substring(1);
}
writer.writeOpenTag(depth, "TAG", false);
writer.writeAttribute("name", name);
writer.print(">");
writer.print(tag.text());
writer.writeCloseTag("TAG");
writer.println();
}
protected void writeParamTag(int depth, ParamTag tag)
{
writer.writeOpenTag(depth, "PARAM", false);
writer.writeAttribute("name", tag.parameterName());
writer.print(">");
writer.print(tag.parameterComment());
writer.writeCloseTag("PARAM");
writer.println();
}
protected void writeParameters(Parameter[] params)
{
for (int i = 0; i < params.length; i++)
{
writer.writeOpenTag(3, "PARAMETER", false);
writer.writeAttribute("type", params[i].typeName());
writer.print(">");
writer.print(params[i].name());
writer.writeCloseTag("PARAMETER");
writer.println();
}
}
public void classStart(ClassDoc doc)
{
writer.writeOpenTag("CLASS", false);
writer.writeAttribute("modifiers", doc.modifiers());
writer.writeAttribute("name", doc.name());
if (doc.superclass() != null)
{
writer.writeAttribute("parent", doc.superclass().toString());
}
writer.print(">");
writer.println();
writeComments(1, doc);
}
public void classEnd()
{
writer.writeCloseTag("CLASS");
writer.println();
writer.flush();
}
public void interfaceStart(int count)
{
writer.writeOpenTag(1, "INTERFACES");
writer.println();
}
public void interfaceDoc(ClassDoc doc)
{
writer.writeSimpleTag(1, "INTERFACE", doc.name());
writer.println();
}
public void interfaceEnd(int count)
{
writer.writeCloseTag(1, "INTERFACES");
writer.println();
}
public void packageImportStart(int count)
{
writer.writeOpenTag(1, "PACKAGEIMPORTS");
writer.println();
}
public void packageImportDoc(PackageDoc doc)
{
writer.writeSimpleTag(2, "PACKAGE", doc.name());
writer.println();
}
public void packageImportEnd(int count)
{
writer.writeCloseTag(1, "PACKAGEIMPORTS");
writer.println();
}
public void classImportStart(int count)
{
writer.writeOpenTag(1, "CLASSIMPORTS");
writer.println();
}
public void classImportDoc(ClassDoc doc)
{
writer.writeSimpleTag(2, "CLASS",
doc.containingPackage() + "." +
doc.name());
writer.println();
}
public void classImportEnd(int count)
{
writer.writeCloseTag(1, "CLASSIMPORTS");
writer.println();
}
public void fieldStart(int count)
{
writer.writeOpenTag(1, "FIELDS");
writer.println();
}
public void fieldDoc(FieldDoc doc)
{
writer.writeOpenTag(2, "FIELD", false);
writer.writeAttribute("modifiers", doc.modifiers());
writer.writeAttribute("type", doc.type().toString());
writer.print(">");
writer.print(doc.name());
writer.writeCloseTag("FIELD");
writer.println();
}
public void fieldEnd(int count)
{
writer.writeCloseTag(1, "FIELDS");
writer.println();
}
public void constructorStart(int count)
{
writer.writeOpenTag(1, "CONSTRUCTORS");
writer.println();
}
public void constructorDoc(ConstructorDoc doc)
{
writer.writeOpenTag(2, "CONSTRUCTOR", false);
writer.writeAttribute("modifiers", doc.modifiers());
writer.writeAttribute("name", doc.name());
writer.print(">");
writer.println();
writeComments(3, doc);
writeParameters(doc.parameters());
writer.writeCloseTag(2, "CONSTRUCTOR");
writer.println();
}
public void constructorEnd(int count)
{
writer.writeCloseTag(1, "CONSTRUCTORS");
writer.println();
}
public void methodStart(int count)
{
writer.writeOpenTag(1, "METHODS");
writer.println();
}
public void methodDoc(MethodDoc doc)
{
writer.writeOpenTag(2, "METHOD", false);
writer.writeAttribute("modifiers", doc.modifiers());
writer.writeAttribute("return", doc.returnType().toString());
writer.writeAttribute("name", doc.name());
writer.print(">");
writer.println();
writeComments(3, doc);
writeParameters(doc.parameters());
writer.writeCloseTag(2, "METHOD");
writer.println();
}
public void methodEnd(int count)
{
writer.writeCloseTag(1, "METHODS");
writer.println();
}
}