
ORIGINAL DRAFT
XML has quickly become the format of choice for a wide variety of applications. But not all formats are accessible through XML, and migrating formats is often inadvisable. While there are benefits to be gained, there typically are good reasons why developers selected other data formats. It would be nice to have the ability to process these formats with the wide array of emerging XML tools. It turns out to be fairly simple to expose alternative formats without requiring any actual migration. In fact, all you really need to do is implement a suitable XMLReader, which is precisely what we’ll look at in this article.
We’ll implement of a few simple XMLReader variants that show you how to handle three different formats. The first handles simple Java Property files and demonstrates the basic technique. The second reads information directly from a file system, listing both files and subdirectories in a hierarchy that reflects the director structure. The third handles log files and can be used where events follow a columnar format that can be specified using a name, offset and length for each column.
At the apex each of these implementations is an AbstractXMLReader that makes it easy to build XMLReader classes. For each of the demonstration classes, you’ll also find a test class that shows what the output looks like. For both the Java properties and the Log file test, these classes generate a suitable test file. For the file system test, the current directory is assumed to be the root.
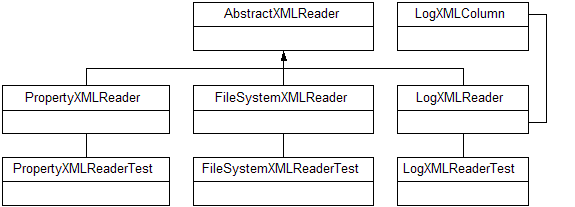
Figure 1: Our example XMLReader classes all inherit from the AbstractXMLReader.
Let’s take a look at the process. In each case, we need an appropriate XMLReader, which has a parse method that takes either a string argument (for a file name) or an InputSource argument. The output gets directed to a SAX parser if you call the setContentHandler with an appropriate handler. For test purposes, we’ll use the Apache Xerces XMLSerializer, but in practice you would typically use either your own SAX ContentHandler or an XSLT processor to handle the output, thus enabling you to do more sophisticated processing or transformations.
The AbstractXMLReader implements the XMLReader interface, which is primarily a set of accessors for features, properties, a ContentHandler, DTDHandler, ErrorHandler and EntityResolver. We’ll use a HashMap to store the features and properties but the AbstractXMLReader doesn’t actually do anything with them. It’s up to your subclass to decide if it needs anything. You can override the setFeature and setProperty methods to reject values you’re not interested in if you like. In any case, your subclass can decide on more specific action or it can ignore either of, or both, the properties and features.
The accessors for the ContentHandler, DTDHandler, ErrorHandler and EntityResolver store and retrieve their values in suitably named instance variables. We’re primarily interested in the ContentHandler, but clearly this technique can be extended to more effectively send errors to the ErrorHandler and may even do validation using a DTDHandler, although the latter is less likely to be important, given that your source content is more tightly controlled than it would be in a typical XMLReader.
Aside from the abstract parse method, which we expect subclasses to implement, we’ll provide three utility methods to make it easy to get a File, InputStream or BufferedReader from the InputSource passed in as an argument. The parse method that takes a String argument calls the abstract parse method, so you don’t have to implement that variant yourself.
Since most of the code in the AbstractXMLReader merely sets or gets an instance variable or a name/value pair in a HashMap, Listing 1 is a code fragment that only shows the code for the parse, getFile, getInputStream and getBufferedReader methods. The getFile method calls the InputSource getSystemId method and returns null if no value was found, wrapping the string in a File object if it wasn’t null. There’s no guarantee that the systemId is a valid path or that the file or directory actually exists.
The getInputStream method calls the InputSource getByteStream method and falls back on the systemId as a file name if the value is null, returning either the byte stream or a FileInputStream if the byte stream was null. The getBufferedReader method tries to get a Reader through the InputSource getCharacterStream method, returning it if it’s not null. Otherwise, we fall back to the getInputStream method and wrap the InputStream in a BufferedReader, using an InputStreamReader filter. You’ll find these methods especially handy when you write your own XMLReader classes.
Listing 2 shows the code for the PropertyXMLReader. We’ll take a closer look and highlight the main methods we expect to call on the ContentHandler, which is really the crux of this technique. Before we start processing, we want to call the startDocument method, calling endDocument right before we finish. These calls need to be first and last, respectively. We then need to call matching pairs of startElement and endElement, with calls to the characters method in some cases in between, or nested calls to the startElement and endElement methods to embed child elements.
Neither the startDocument nor the endDocument methods require any arguments. The startElement and endElement methods expect a namespaceURI, localName and qualifiedName. Unless you’re using namespaces, you can stick to the qualifiedName argument for your tags and leave the other two as empty strings. The startElement method takes an additional Attributes argument.
Since Attributes is an interface, the SAX API provides an AttributesImpl class in the org.sax.helpers package. We can add attributes to this collection by calling the addAttribute method, which expects the same namespaceURI, localName and qualifiedName arguments, along with a type and value. We uses the qualifiedName argument to specify the attribute name, a CDATA type and a string value. Some elements don’t require any attributes but the startElement method still requires an Attributes argument.
If you take a look at the code in Listing 2, you’ll see that the parse method makes sure we have a valid InputStream and reads the Properties instance using the load method. We then call the startDocument method and make a first call to startElement with the root tag, named PROPERTIES. As you can see, there are no attributes in the Attributes list. The processProperties method iterates through each property. When we return from that call, we provide a closing PROPERTIES tag by calling the endElement method and make sure we call endDocument when we’re done.
The processProperties method gets a key Iterator from the Properties object, which is actually a subclass of HashTable, and walks that key set one entry at a time. On each pass, we do a lookup for the value, using the key, and call the startElement, characters and endElement methods on the ContentHandler. You’ve seen how the startElement and endElement methods work. In this case, we provide a name attribute, which uses the Properties key as its value.
The characters method expects a character array, offset and length arguments. In our case, the offset will always be zero and the length will be the length of the property string value we’re currently processing. We can easily get a character array from a String by calling the toCharArray method.
That’s all there is to it. You can do more if you like, but those are the basics, applicable to virtually any other example format. In some cases, you’ll have to convert values to make sure reserved characters like the ‘<’ and ‘>’ characters don’t occur in the text. You’ll have to convert any non-text value to appropriate text and some characters should be coded as entities (like the ‘>’ entity, which replaces the ‘<’ if you still need one within the text). Otherwise this process is pretty uncomplicated.
Rather that explore listings for the two other examples, I’ll cover them briefly and invite you to download them from the web. The text that follows should be clear enough without having the source in front of you. The code should make sense to you when you look at it later.
The FileSystemXMLReader shows how easy it is to handle a tree structure by recursively traversing a file system, or some portion thereof. You can specify the root directory when you call the parse method. Like the PropertiesXMLReader, we call startDocument first and endDocument last. We process each directory starting with the root recursively, branching on the basis of whether the element we’re dealing with is a file or directory object. In the case of a directory, we use a name attribute in the startElement call and recurse through its children before closing with a call to endElement. For files, we specify a size attribute and use a call to the characters method to specify the file name as content.
The LogXMLReader is slightly more interesting. For each entry in the log, we break up the elements based on their column position. This code could be much more sophisticated, but this is enough to demonstrate it’s usefulness. We use a LogXMLColumn object to specify each field by name, offset and length. If the length is -1, we read right through to the end of the line.
The LogXMLReader reads each line and breaks it up into name/value pairs. Each name comes from the getName method in the LogXMLColumn object being processed and the value is parsed by calling the parseLine method, which uses a call to substring to do the parsing. A more useful parsing algorithm may be more useful in real-world logging situations, but the principles are the same. In each case, the XML output uses a root tag named LOG, a set of children named ENTRY for each line, along with a set of elements named after the components of a line.
The semantics of a log file depends heavily on the source format, so I’ve used a simple approach to demonstrate the technique. What’s important here is the notion of using XML tools to do log file analysis. It’s easy to write filters or to apply transformations with XML. These are common requirements when analyzing log files. What’s more, with a few XMLReader implementations to handle different log file formats in a large, distributed system, it’s easy to converge on a common format for analysis. It’s also easy to use data warehousing solutions since most relational database engines now support XML.
Writing your own XMLReader implementation is a powerful technique, making it possible to use XML tools to process non-XML formats. This process is simplified by using an AbstractXMLReader from which concrete classes can inherit common behavior, freeing developers to focus on the specifics of a given file or stream format. With a few concrete examples, including a PropertyXMLReader, a FileSystemXMLReader and a flexible LogXMLReader, it’s easy to see how you can apply this approach to different data formats. I hope you find this technique as useful as I have.
Listing 1
import java.io.*;
import java.util.*;
import org.xml.sax.*;
public abstract class AbstractXMLReader
implements XMLReader
{
// Variable Declarations and Accessors now shown...
public void parse(String systemId)
throws IOException, SAXException
{
parse(new InputSource(systemId));
}
public abstract void parse(InputSource source)
throws IOException, SAXException;
protected File getFile(InputSource source)
throws IOException
{
String systemid = source.getSystemId();
if (systemid != null)
{
return new File(systemid);
}
return null;
}
protected InputStream getInputStream(InputSource source)
throws IOException
{
InputStream input = source.getByteStream();
if (input != null) return input;
String systemid = source.getSystemId();
if (systemid != null)
{
return new FileInputStream(systemid);
}
return null;
}
protected BufferedReader getBufferedReader(
InputSource source) throws IOException
{
Reader reader = source.getCharacterStream();
if (reader != null)
{
return new BufferedReader(reader);
}
InputStream input = getInputStream(source);
if (input != null)
{
reader = new InputStreamReader(input);
return new BufferedReader(reader);
}
return null;
}
}
Listing 2
import java.io.*;
import java.util.*;
import org.xml.sax.*;
import org.xml.sax.helpers.*;
public class PropertyXMLReader
extends AbstractXMLReader
{
public PropertyXMLReader() {}
public void parse(InputSource source)
throws IOException, SAXException
{
InputStream input = getInputStream(source);
if (input == null)
{
throw new IOException(
"Unable to get input stream");
}
Properties properties = new Properties();
properties.load(input);
input.close();
contentHandler.startDocument();
AttributesImpl attributes = new AttributesImpl();
contentHandler.startElement(
"", "", "PROPERTIES", attributes);
processProperties(properties);
contentHandler.endElement(
"", "", "PROPERTIES");
contentHandler.endDocument();
}
public void processProperties(Properties properties)
throws IOException, SAXException
{
Iterator iterator = properties.keySet().iterator();
while (iterator.hasNext())
{
String key = (String)iterator.next();
String value = properties.getProperty(key);
AttributesImpl attributes = new AttributesImpl();
attributes.addAttribute(
"", "", "key", "CDATA", key);
contentHandler.startElement(
"", "", "PROPERTY", attributes);
contentHandler.characters(
value.toCharArray(), 0, value.length());
contentHandler.endElement("", "", "PROPERTY");
}
}
}